
这一章主要是四个内容:
- 简单的datapath
- 流水线(pipeline)
- 冒险及处理(hazard)
- 例外及处理(exception)
Intro
- CPU performance factors
- IC
- CPI & Cycle time
- 两个RISC-V的实现
- 简单版本
- 更加流水的现代化版本
- 三种指令
- 访存指令
lw,sw - 算数逻辑运算
add,sub,and,or - 控制跳转
beq
- 访存指令
指令执行
- PC -> instruction memory, fetch instruction
- Register numbers -> register file, read registers
- 依赖于指令类型
- 使用 ALU 进行运算
- 算数结果
- 用于访存的内存地址
- 分支比较
- 为load/store 访问data memory
- PC <- target address 或 PC + 4
- 使用 ALU 进行运算
CPU 的修炼之路
CPU Overview(最简单版本)
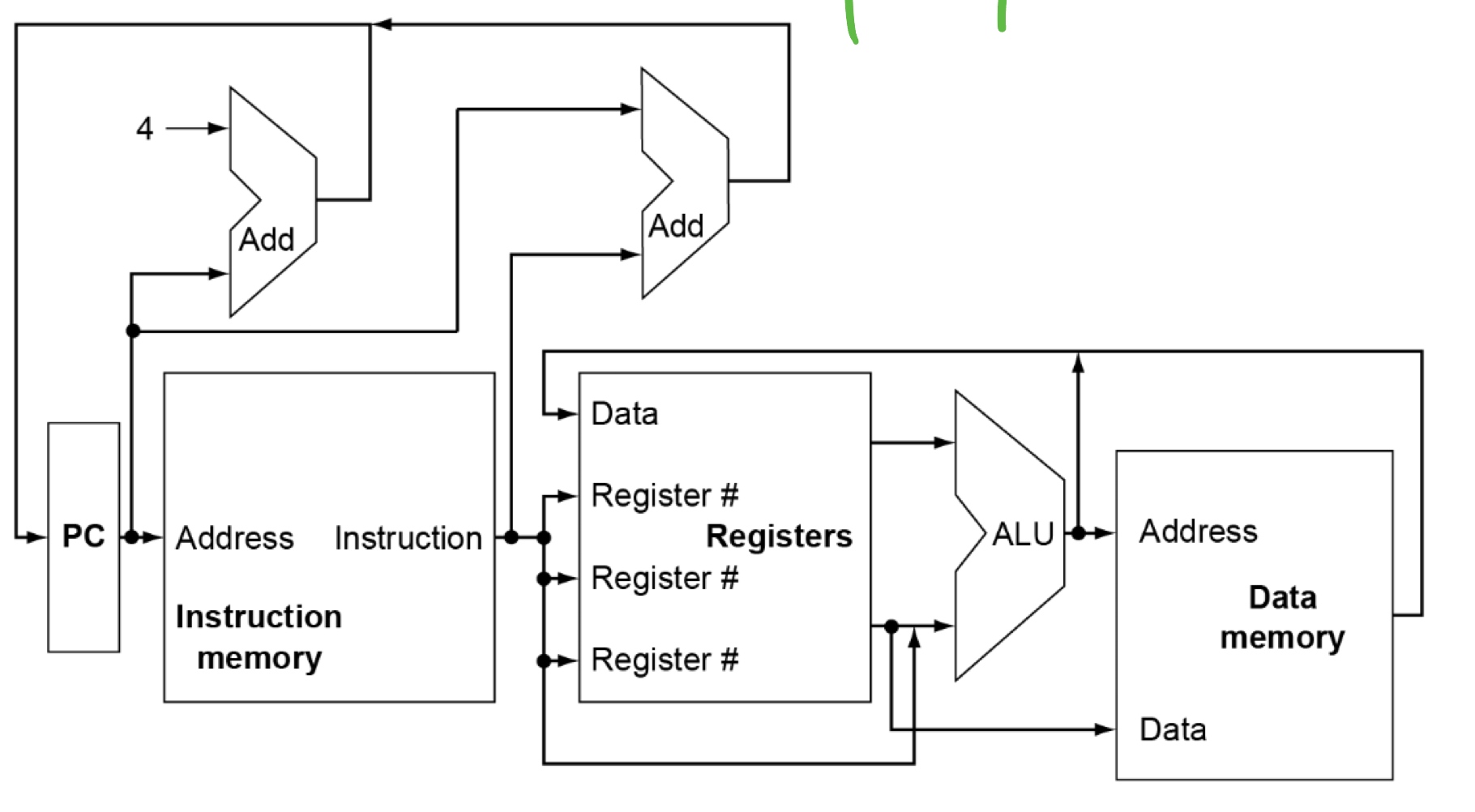
对于上面的版本,某些地方不能仅仅是把线连在一起,对于不同的指令要进行不同的选择(选择数据来源和将要进行的操作)
比如PC 是 +4 还是进行 相对寻址,数据写回 Register files 的时候是写回算数运算结果还是data memory,在ALU进行运算的是rs2 还是 imme,都要进行选择,此时我们在以下三个地方加上复选器(Multiplexer):
- ALU 的 rs2 与 imme ( add or addi )
- 写回的PC (选择是 PC + 4 还是 相对寻址)(PC + 4 or beq)
- 写回register file 的data(选择是ALU运算结果 还是 data memory)(算数运算指令 or load)
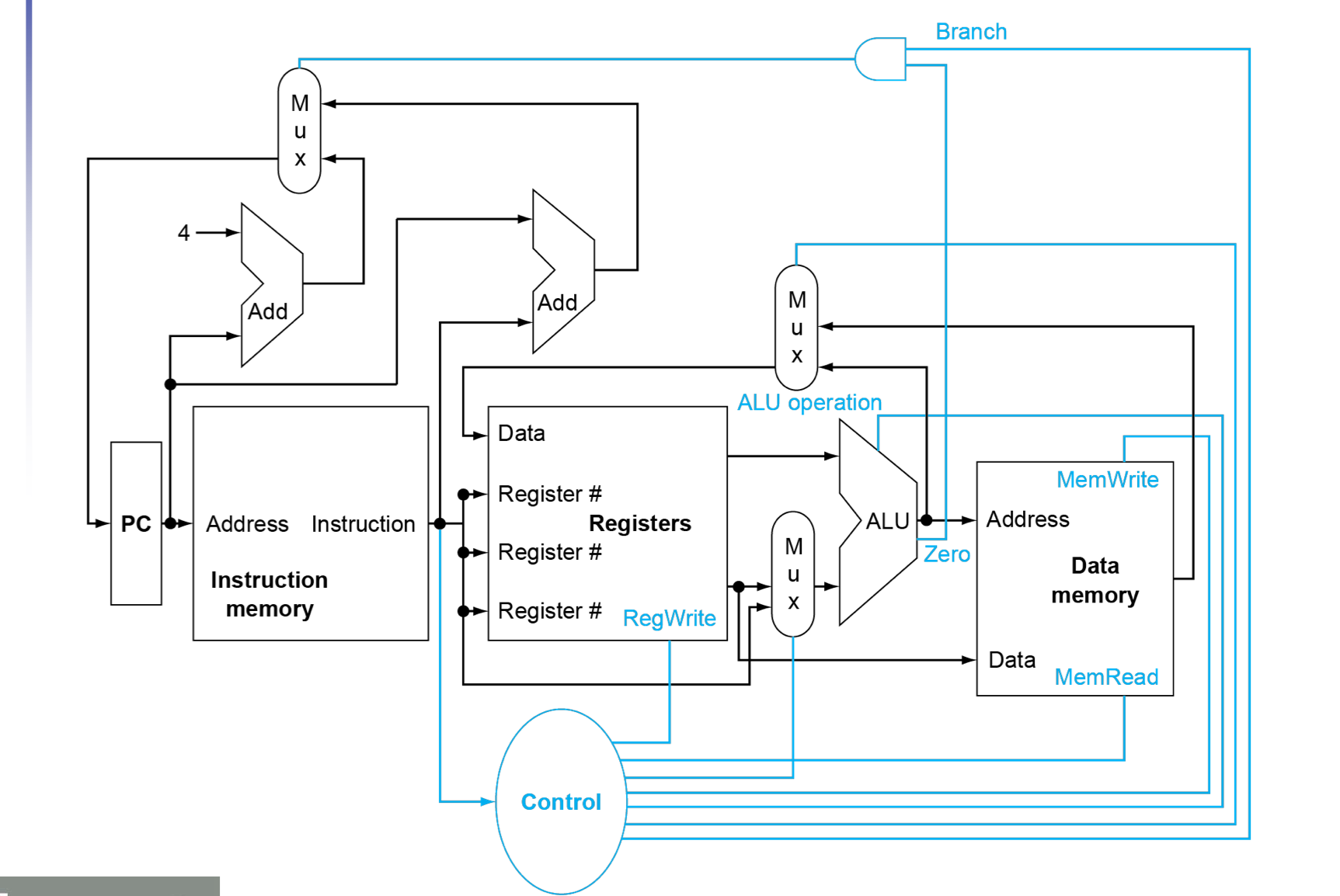
改进后为下面的版本
Control(加上复选器版本)
逻辑设计基础
- 信息是以二进制进行编码的
- 低电平为0,高电平为1
- 每个bit 为一条线
- 多个bit 则在 多条线上编码
- 组合元件
- 在data上进行操作
- 输出完全由输入决定(输出是输入的函数)
- 状态元件
- 存储信息
- 输出不仅由输入决定,还由自身状态决定
时钟同步方法
- 组合逻辑在时钟周期循环的时候处理data
- 组合逻辑单元的操作在一个时钟周期内完成
- 从一个状态单元输入,再输出到一个状态单元
- 最长的延迟决定了时钟周期

构建数据通路
- Datapath
- 在CPU中处理数据和地址的元件
- register,ALU,mux‘s,memories
- 在CPU中处理数据和地址的元件
- 我们将逐步构建RISC-V的datapath
- 重构 overview版本
处理指令的5步操作:
- Instruction Fetch(读取指令)
- PC
- Instructor Memory
- Adder (对PC进行操作)
- Instruction decode (对数据进行解码,对不同的指令采取不同的措施)
- Reg
- Execution(执行指令,进行算数操作)
- ALU
- Memory(进行访存)
- Data Memory
- Write Back(写回数据)
- Reg
需要注意的是并不是所有的指令都要进行上述5步,比如addi不需要进行第四步,load需要进行所有步骤。(这里隐隐显示了单周期的一个弊端)
- Reg
接下来我们对上述5步逐步构建所需要的元件,一步一步地构建出一个数据通路
Instruction Fetch
读取指令需要从Instruction memory中进行读取,读取完毕之后还需要对PC + 4由此可以构建出以下元件![[Instruction fetch.png]]
算数/逻辑运算
对于R-Format指令
- 读取两个需要操作的寄存器
- 执行算数/逻辑操作
- 写寄存器结果
这样来说有两个组件参与上述过程
- register files
- ALU
由此可以构建下面的元件(下面是针对I-Format指令,多一个立即数生成器同时进行sign extension)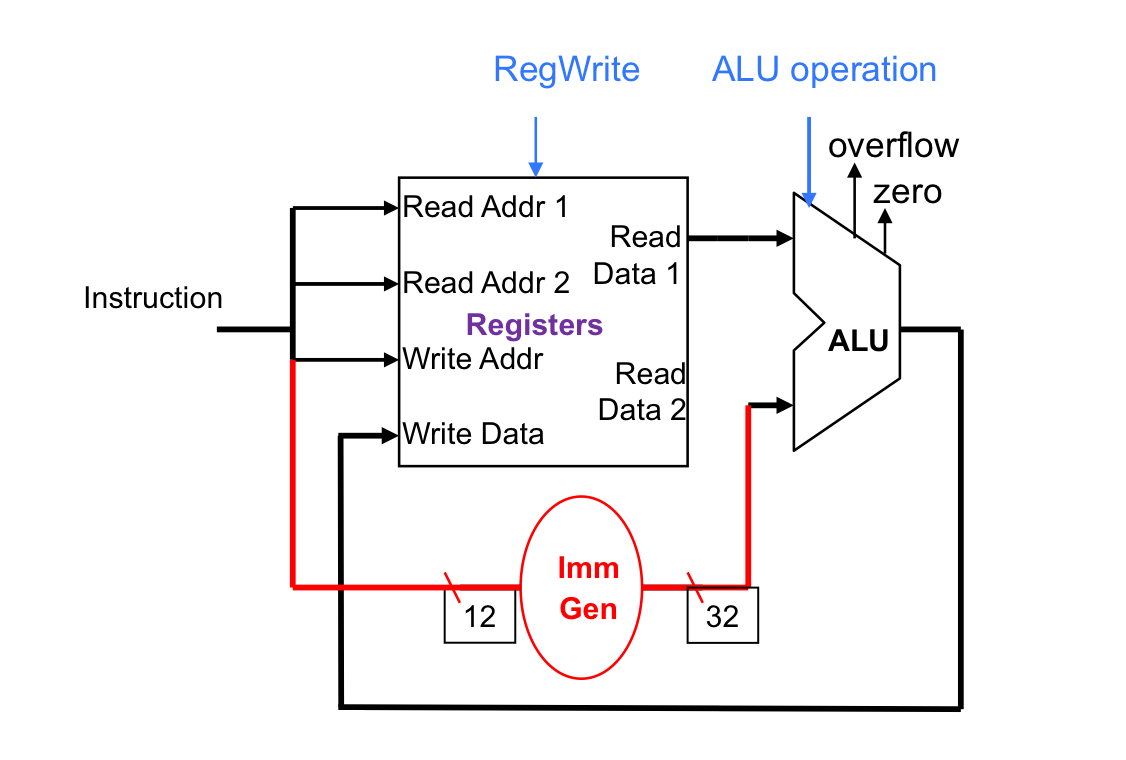
访存指令(Load/Store)
- 读取操作寄存器
- 用12位偏移量进行地址操作
- 使用ALU,并且是sign-extension
- Load:读取memory并且更新register
- Store:将register值写入memory
那再在上面算数运算元件的基础上,再补充上访存对于data memory 的操作
对于Load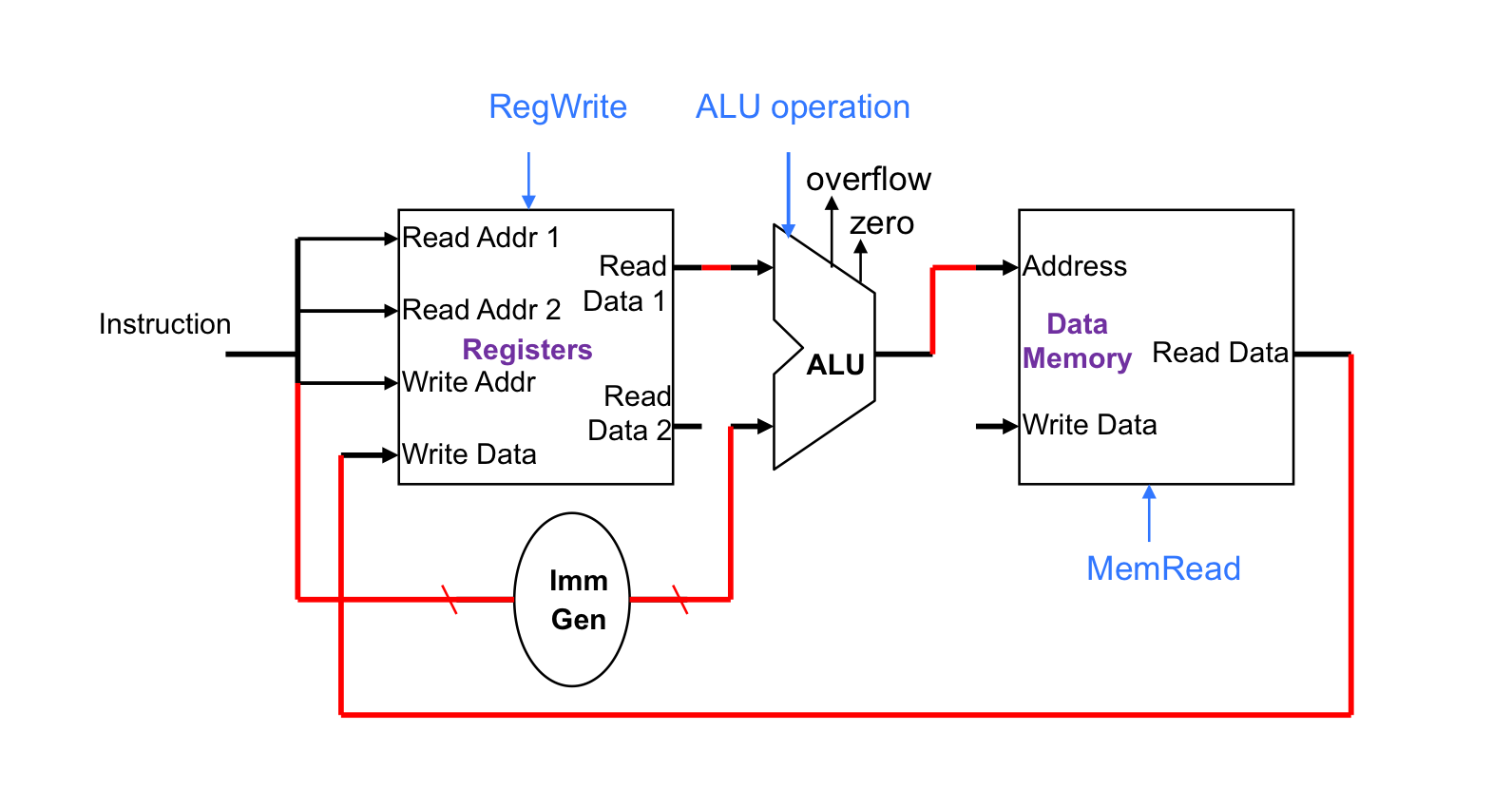
对于store: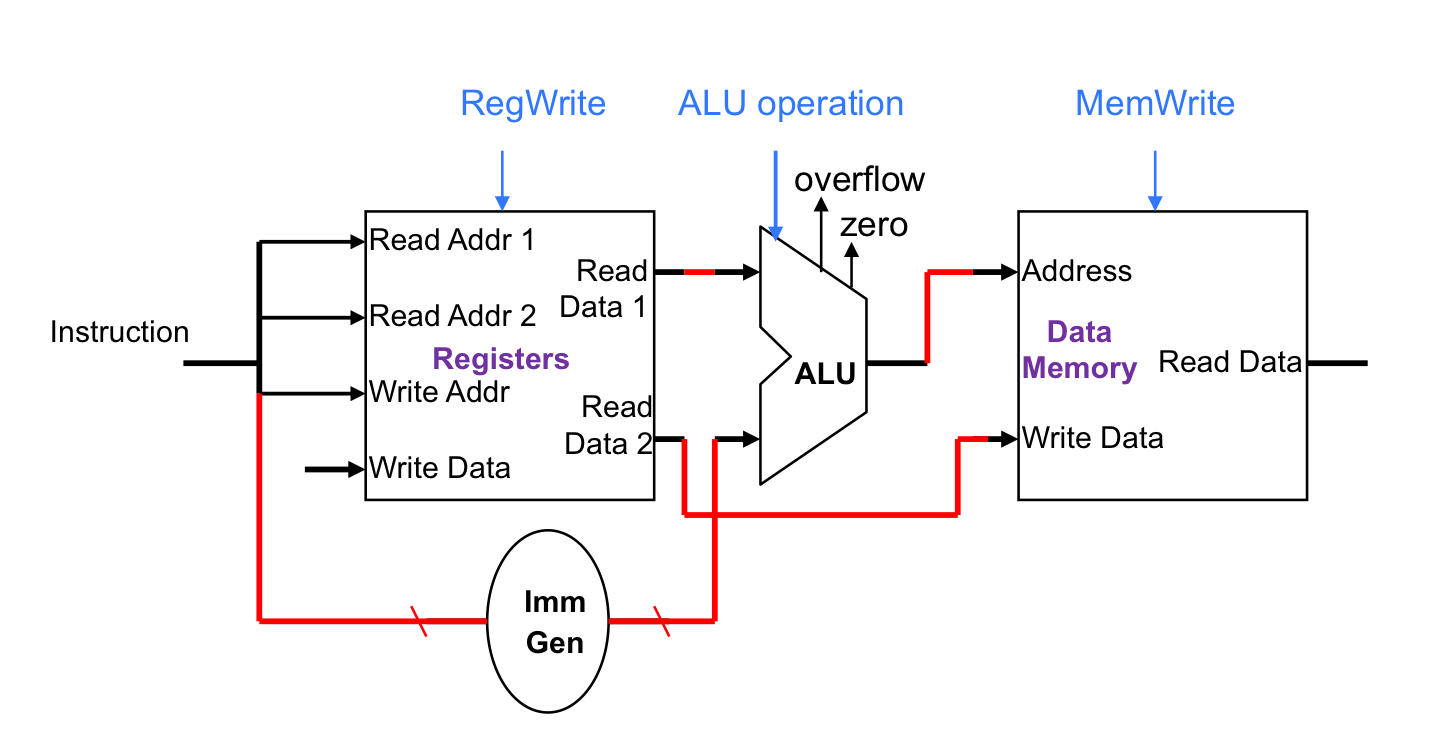
将上面的元件组合起来
- 单周期数据通路在一个时钟周期内只进行一条指令
- 每一个datapath一次只能执行一个函数
- 因此我们需要讲instruction memory 和 data memory分开
- 具体一点来说是由于每个时钟周期只能执行一条指令,如果将date和instruction混在一起,对于一个单接口的memory是无法同时进行两个不同的访问的
- 使用multiplexer来选择数据来源和将要进行的操作。
于是我们可以对于R- Format/Load/Store 指令构建下面的数据通路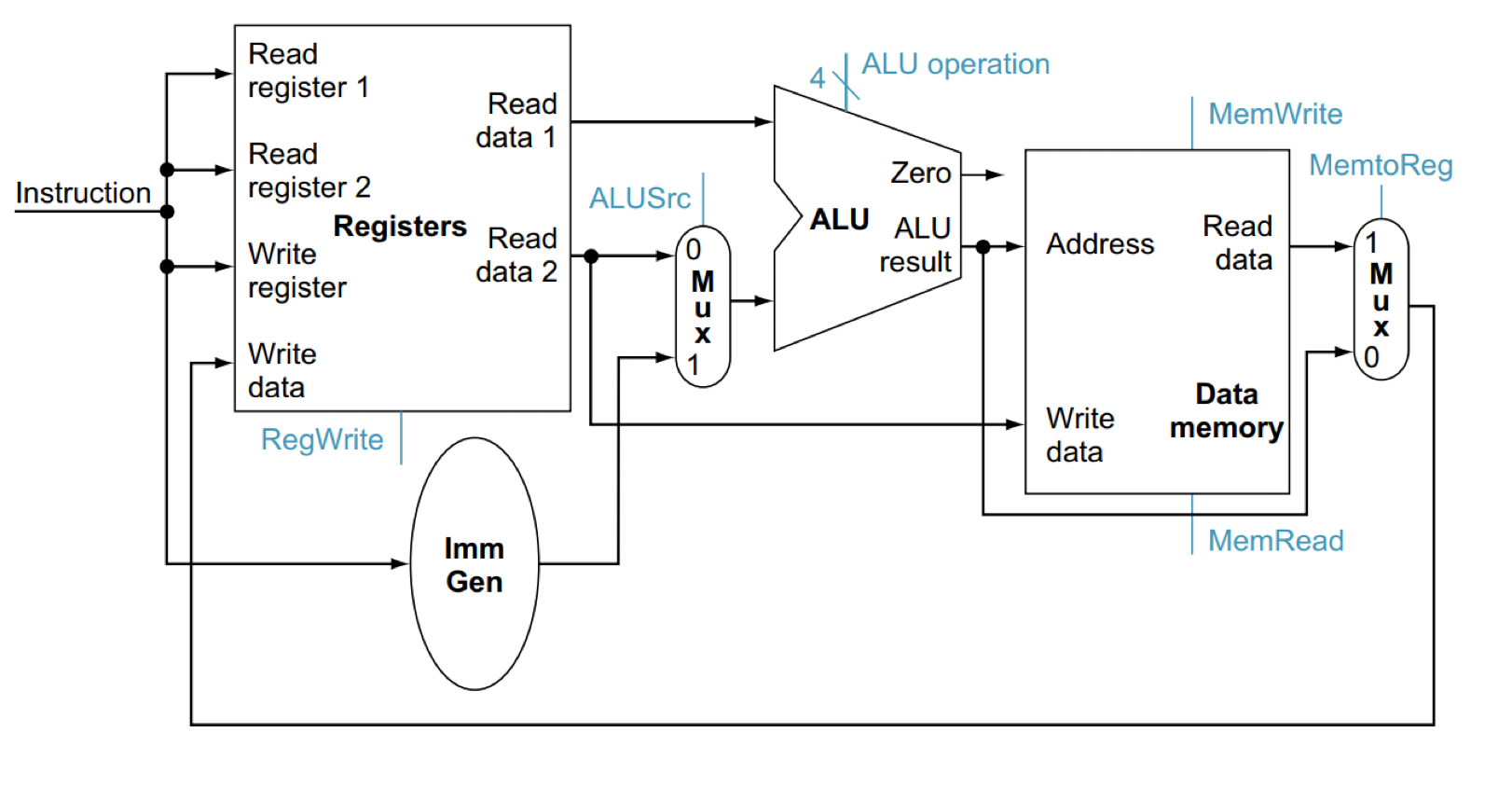
跳转指令(Branch)
- 读取操作寄存器
- 比较两个操作数
- 使用ALU,相减然后与0进行比较
- 计算目标地址
- sign-extension
- 左移一位(以halfword为单位)
- 加到PC上(PC相对寻址)
将上述功能加入到进行Instruction Fetch的组件中,可以构建下面的元件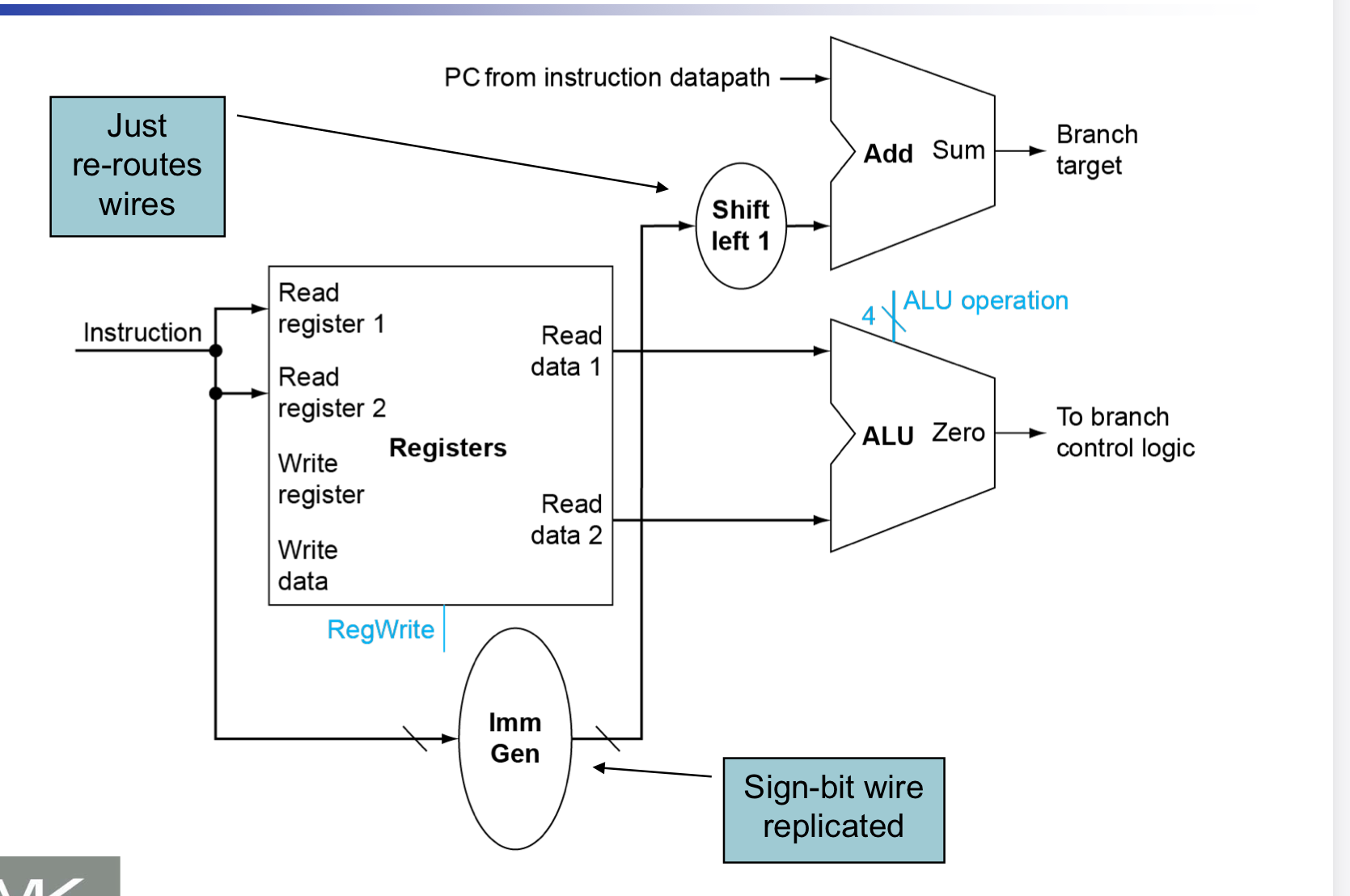
Full Datapath
由此我们已经完成构建了完整的数据通路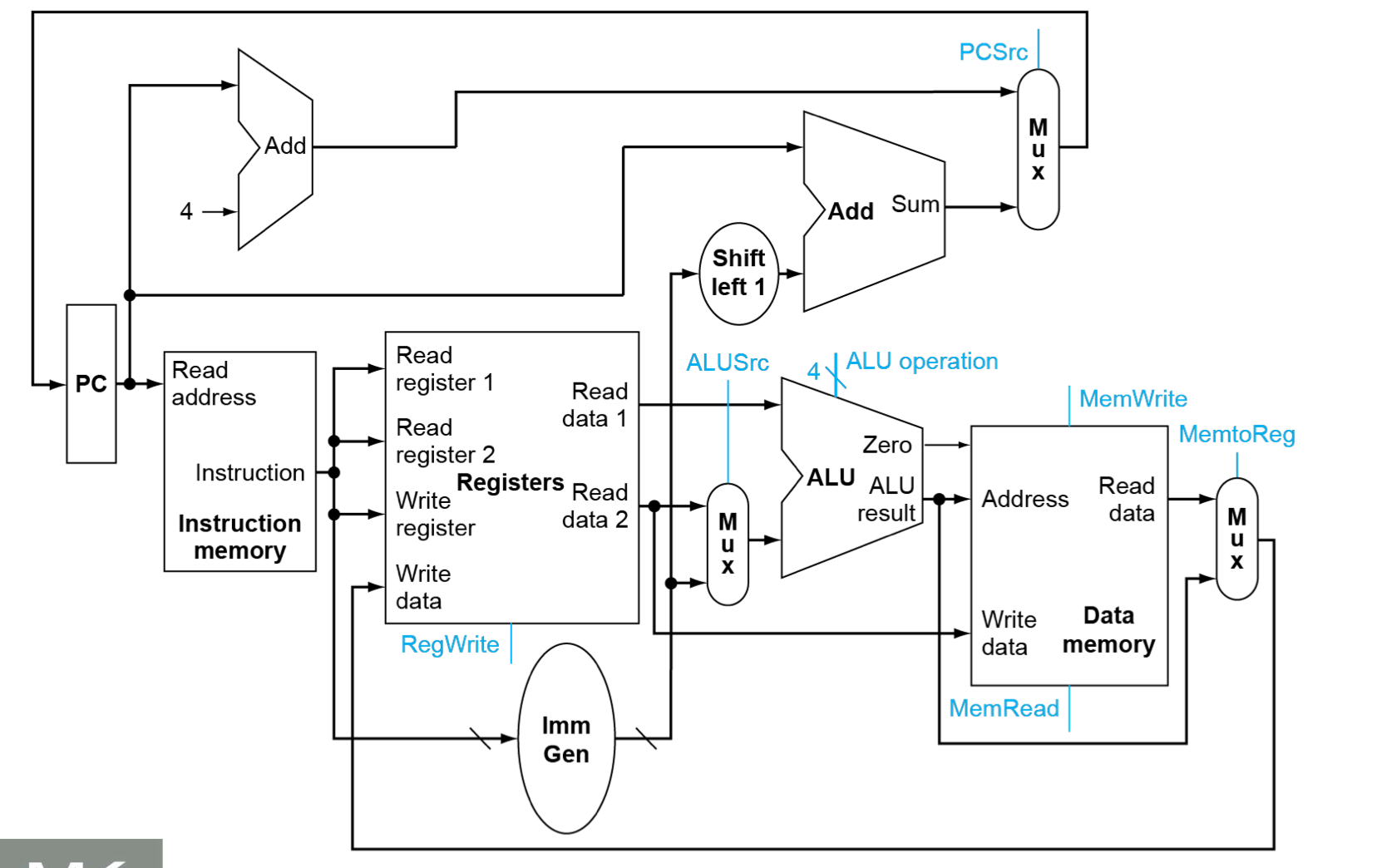
当然对于上面的数据通路还有一些使能端没有提及,在这里说明一下
- RegWrite(用于对写回寄存器堆进行使能)
- MemWrite,MemRead (对于读写内存进行使能)
在不同的指令执行时使能端也发生相应的变化。
ALU Control
ALU 会被用于以下操作
- Load/Store:F = add
- Branch: F = subtract
- R-type: F depends on opcode
我们认为 ALUOp 由 opcode 衍生而来
通过解码指令的opcode,func3,func7 字段来得到ALU 的运算操作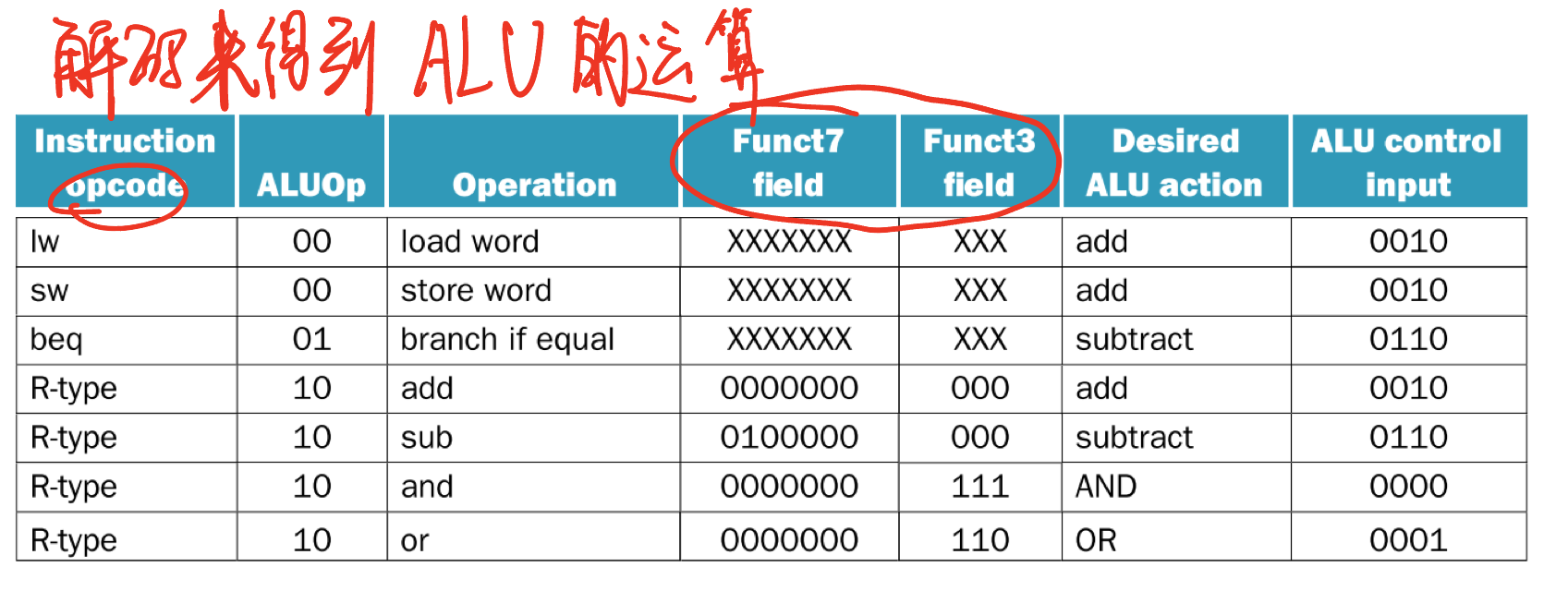
Control signals dirived from instruction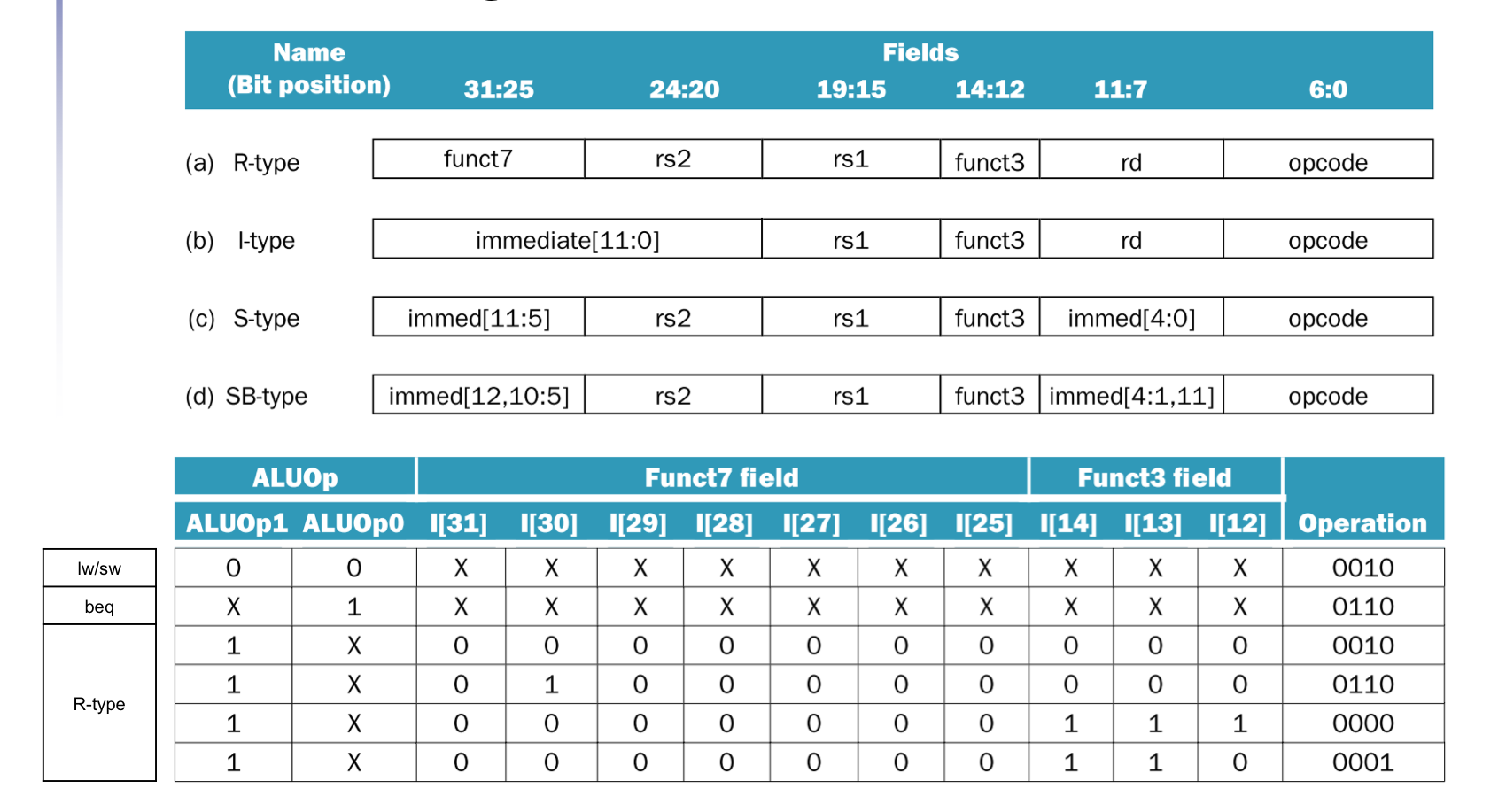
引入Control之后,我们又可以将Instruction Decode这一步加入到datapath中了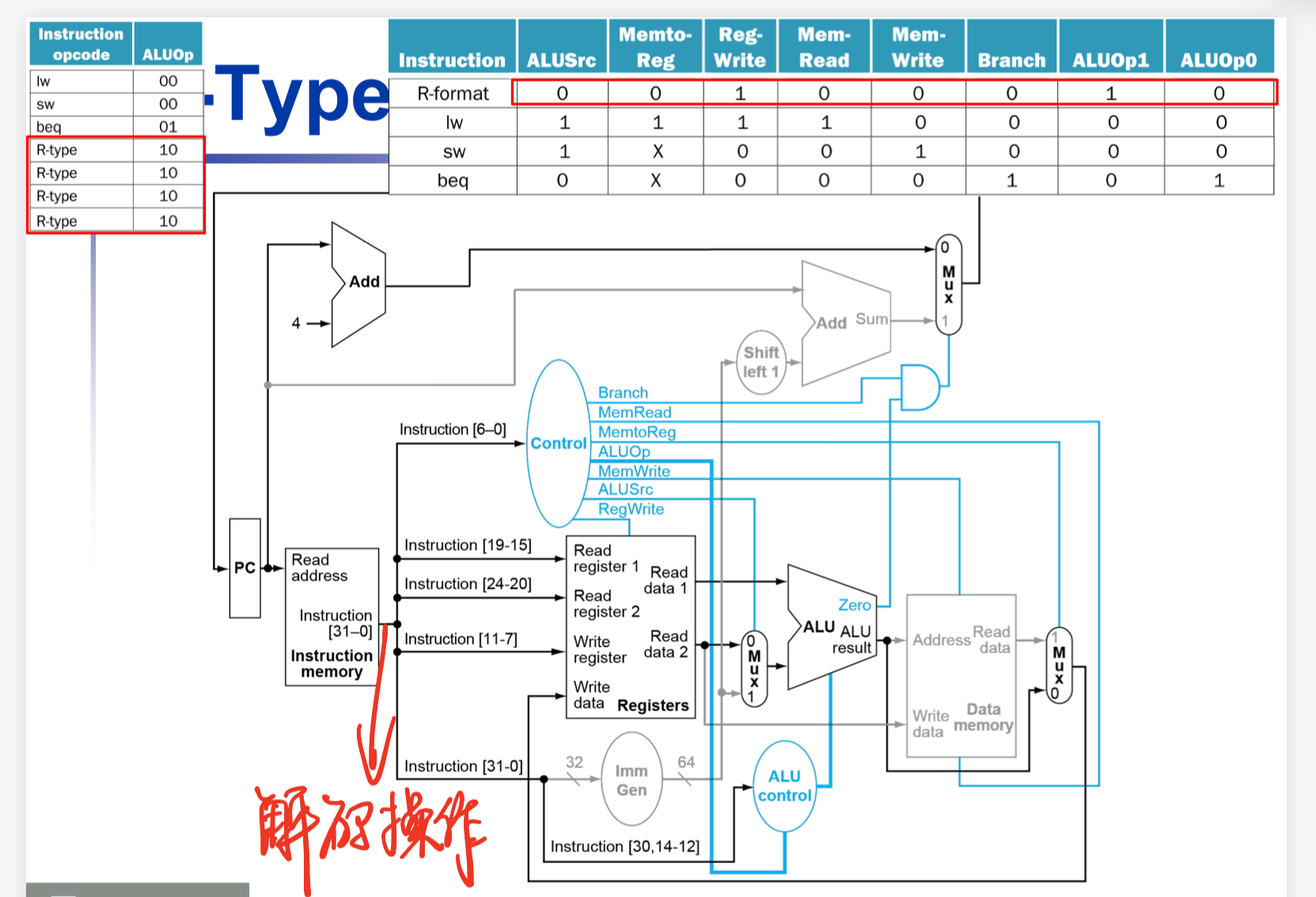
上面的图中发现我们在Instruction Memory和register file之间多了一道对Instruction 进行解码的操作,根据不同的字段来对不同的接口进行操作
- 操作寄存器(rs1,rs2, rd字段)
- 操作立即数生成器(imme字段)
- 操作ALU(func3 & func7字段)
- 操作multiplexer(opcode字段)
至此,单周期数据通路的构建已经完成。
根据我们处理instruction的5步,我们构建数据通路的步骤却是不一样的
- Instruction Fetch(拿到指令)
- Instruction memory
- register files
- PC(PC +4)
- Execution(进行运算),WriteBack(将算数运算结果写回)
- ALU(R-Format,I-Format,SB-Format)
- Adder(beq)
- Memory(访存),WriteBack(将地址load回)
- Data Memory(Load/Store,
- Instruction Decode(对指令进行解码)
- Instruction memory
- register file
- ALU Control
- Immediate generator
- multiplexer control
性能问题
- 最长的延迟决定了周期时长
- 关键的path:load(5步都需要进行)
- Instruction Memory -> register file -> ALU -> data memory -> register file
- 对于不同的指令是不可变的
- 违反了design principle
- “ Making the Common Case Fast”
- 我们将要通过流水线(pipeline)来改进性能
流水线
洗衣服
用洗衣服对流水线做类比,每次洗衣服有四个步骤
- 洗衣服
- 烘干
- 叠衣服
- 收纳
对于单周期而言,只有上面四个步骤都做完后才可以开始执行下一套流程,而对于流水线,在一个步骤执行完之后,这个步骤所需的工具不会停止工作,每个步骤所需的工具的工作状态是可重叠的,如下图: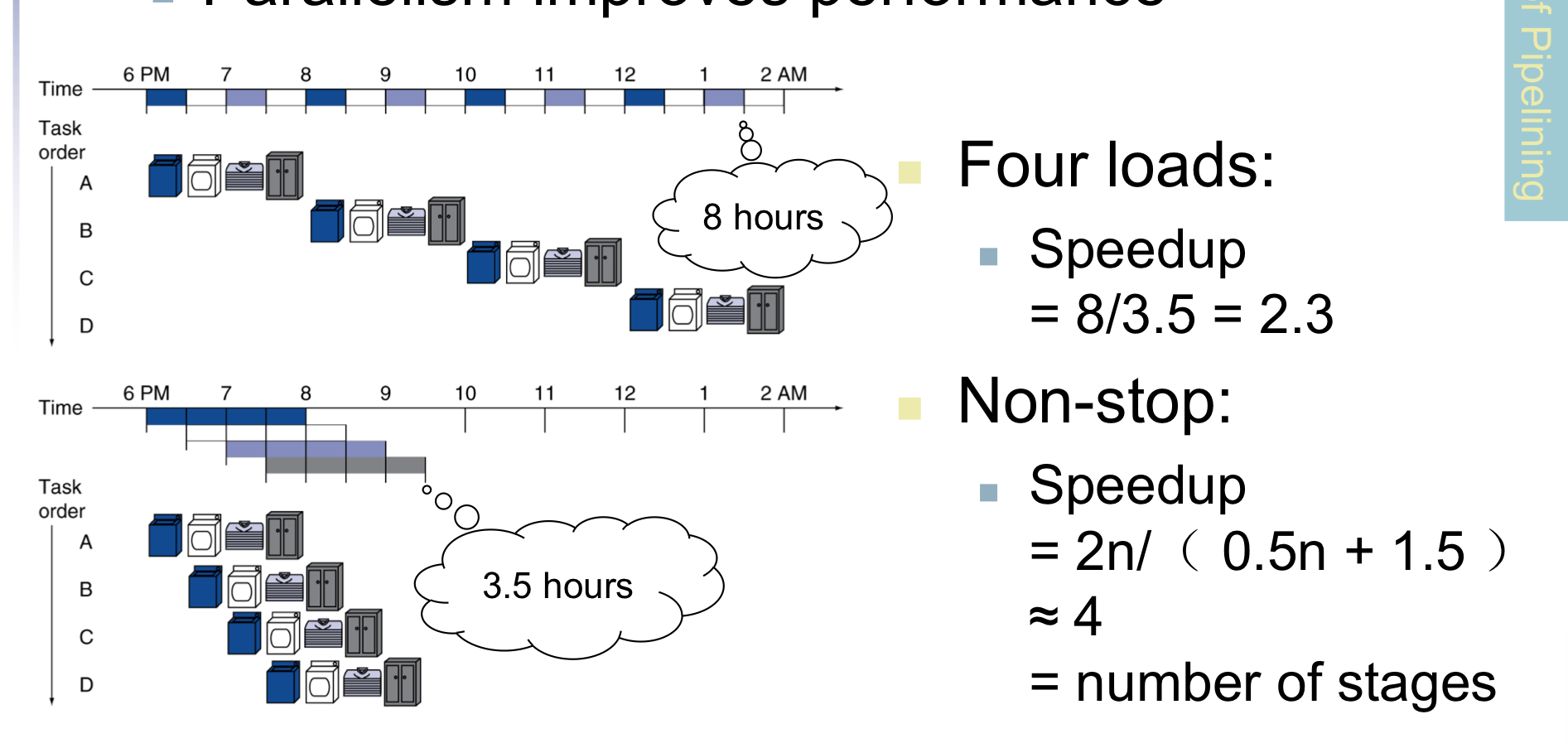
这种流水线式的工作方式明显提高了性能,最后每个步骤的工具都在工作,相比单周期而言,流水线有多少步骤就提高了多少倍的速度
五个阶段
- IF:Instruction fetch from memory
- ID:Instruction decode & register read
- EX:Execute operation or calculate address
- MEM:Access memory operand
- WB:Write result back to register
性能分析
假设每个阶段的时间
- 100ps for register read or write
- 200ps for other stages
通过下图可以看到单周期与流水线的性能差异: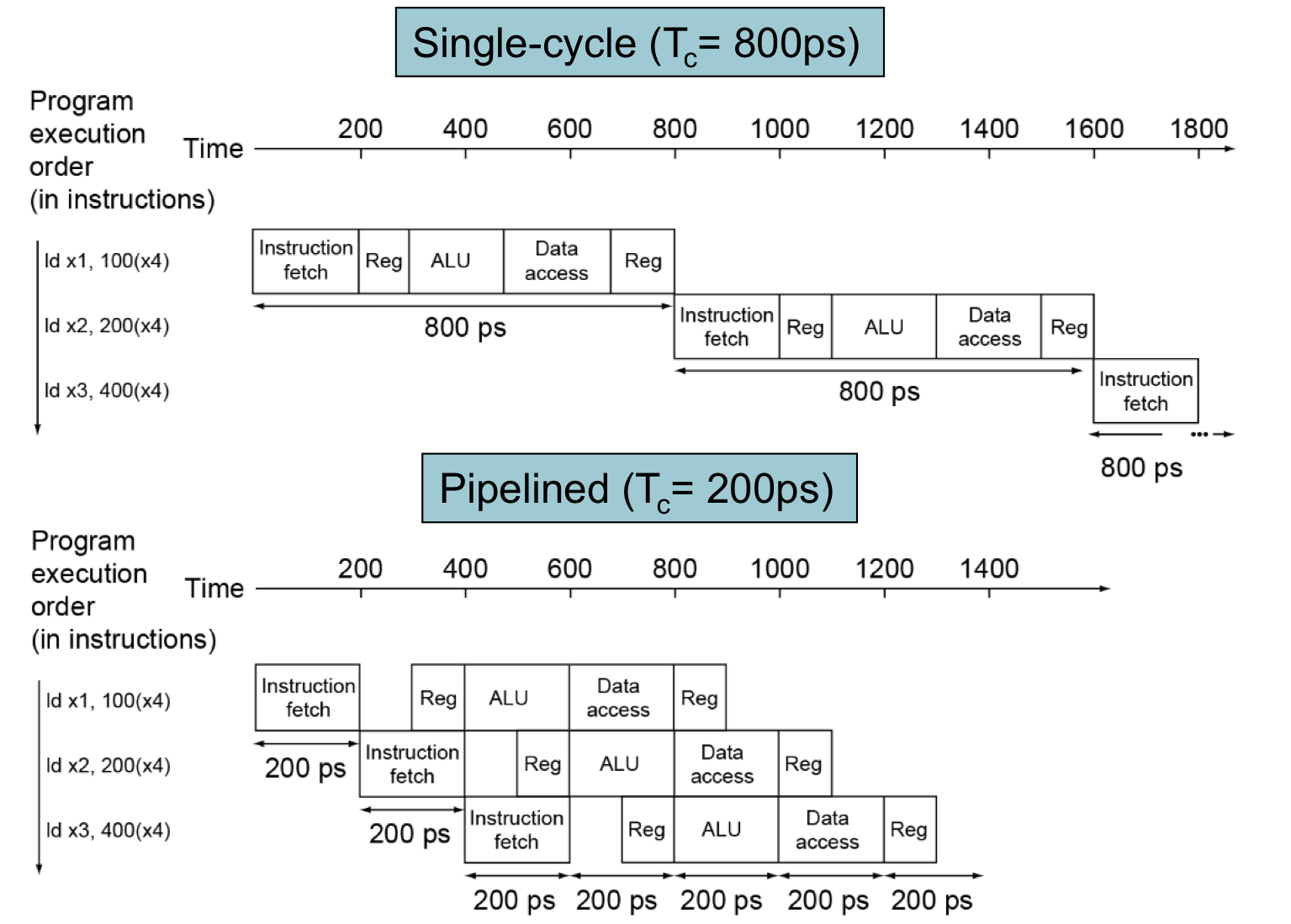
通过上图可以总结出以下几点: - 如果所有的stage花费同样的时间
- 那么pipelined time = no pipelined time / number of stages
- 如果stages不是balanced那么提速会少一些
- 因为pipeline的时钟周期根据最长的stage time而定,即使stage time < cycle time实际上还是需要经过一个cycle time才会到下一个stage
- 因为有throughput才会有提速
- 而每个instruction的延迟没有减少
ISA design
- RISC-V对于流水线的设计
- 所有指令都是32-bits
- 在一个cycle里面fetch和decode都更加容易
- x86甚至有少达1-bit 多达17-bit的指令也是时代的奇葩了
- 更少且更规整的格式
- 可以在一步内同时完成 decode 和 read register
- Load/Store 地址
- 可以在第三个stage计算地址,在第四个stage访问内存,将计算和访问分开
- 所有指令都是32-bits
Hazards
- 阻挠在下个周期开始执行下一条指令的情形
- 结构冒险
- 需要的资源繁忙
- 数据冒险
- 需要等待上一条指令完成data read/write
- 比如上一条addi 需要存入x5,而下一条指令又需要read x5,这时就会发生冒险
- 控制冒险
- 上一条指令决定了控制行为
- 比如上一条为beq,那么如何判断下一条指令是PC + 4还是需要PC 相对寻址呢
How to solve Hazards
怎么解决流水线设计中出现的冒险问题是本章的重点
struct hazard
解决结构冒险没啥好说的,主要就是将一个memory 分为 instruction memory 和 data memory
矛盾出现在资源的利用上,指令和地址
在只有一个memory 的RISC-V流水线中
- load / store需要访问data
- 那么instruction fetch会造成阻塞
- 产生pipeline bubble
- 必须要等取data完成之后再进行instruction fetch(one-ported)
- 因此流水线通路需要instruction和data 分离的memory
- 或者分离的instruction和data 内存
data hazard
后一条指令依赖于前一条指令的data access
一种方式是直接使用bubble,阻塞直到上一条指令完成再执行下一条指令
当然这种方式在设计时是不可取的,极大的浪费了性能
另一种方式被称为前递或旁路(Forwarding a.k.a Bypassing)
当需要的结果产生的时候就直接把它取过来使用
- 不需要等到它被存储到register中
- 在datapath中需要额外的connection来进行这个操作
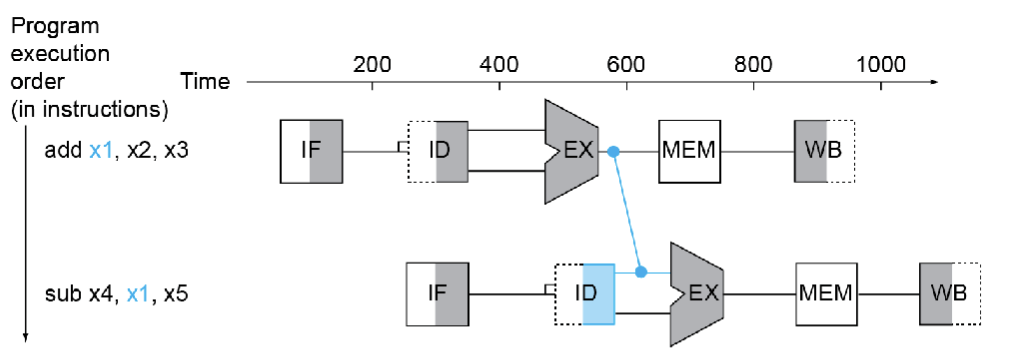
Load-Use Data Hazard
当然通过上面这种方式也不一定每次都可以防止阻塞
- 结果在需要的时候还没有被计算出来
- 不能时间回溯(也就是上面蓝色的connection不能往时间轴的前面伸)
在Load-Use指令执行的时候,我们只有在MEM访问内存的时候才能得到我们想要的(存在内存中的)结果,如果我们还是不插入阻塞的话,这个蓝色的connection就会往回链接,显然这是违背因果律的,因此我们还是需要插入bubble
代码规划来规避阻塞

在上面的RISC-V指令中我们可以看到,在这一条c代码中,本来是两条Load-Use指令,会产生两次阻塞,但是我们将Load-Use-Load-Use改进为Load1-Load2-Use1-Use2,改变了Load-Use结构,消除了阻塞,优化了性能。
Control Hazards
- 分支决定了flow of control
- fetch下一条指令取决于branch的结果
- 流水线不一定每次都能fetch到正确的指令
- 还在instruction decoding的时候下一条指令就已经进入instruction fetch了
- 在RISC-V 流水线中
- 需要在流水线中早早地比较register并计算target
- 添加硬件来在instruction decode的时候就完成这个工作
一种方式是直到branch outcome计算完成后再fetch,当然这种方式不可避免地会引入阻塞
Branch Prediction
- 更长的流水线不能完美的随意的早早决定branch outcome
- 阻塞惩罚也更加不可接受(长流水线的性能昂贵)
- 预测branch的结果
- 只有在预测错误的时候才会引入阻塞
- 在RISC-V流水线中
- 可以预测没有被take的branch
- 在branch之后再fetch instruction,没有延迟
更加现实的Branch Prediction
- 静态branch 预测
- 基于典型的branch 行为
- 比如:循环和if语句
- 一个是预测会向回跳转
- 一个是预测branch没有执行,向前执行
- 动态branch预测
- 硬件解决真正的branch behavior
- 比如记录下branch的跳转历史
- 假设未来的behavior会继续这个趋势
- 如果假设错误,那就加入阻塞并重新fetch,然后更新history
- 硬件解决真正的branch behavior
举个例子:
在一段代码中遇见循环时,我应该预测向回跳转,遇见其他情况我应该直接预测不跳转(因为但我们单独写一些if语句时,一般都是针对特殊情况),在未进入循环时,我们预测不跳转,刚进入循环时,仍然预测不跳转(因为硬件也不知道是否进入了循环),但是此时实际上会连续几次发生跳转,此时我们就要更改预测策略,预测会发生跳转,当循环结束后,仍然还会预测发生跳转(因为硬件也不知道循环已经结束了),实际上已经不发生跳转了,那么我们又要改变回我们原来的预测不发生跳转的策略,这就是动态branch prediction。(硬件会根据历史记录来假定未来趋势,其余仅仅是在执行指令,并不能立刻的判断出循环是否结束,也就是说,硬件是具有“惯性的”)
pipeline 总结
- pipeline通过改进instruction throughput来提升性能
- 并行执行数量繁多的instruction
- 每条指令具有相同的latency
- 受hazard的影响
- structure,data,control
- 指令集的设计会影响pipeline实现的复杂度
pipeline register (流水线寄存器)
在不同的stage之间需要寄存器->需要保持在上一个周期内产生的信息
举例:
比如我们在第一个add指令中将x5作为rd,但是在这条指令执行完之前就开始执行下一条指令,假设下一条指令又将x7作为rd,而这时又register file中的rd只能存储一个rd(也就是正在进行ID的rd),我们需要将第一个add指令的rd信息给存储下来,让这个信息跟着这条add指令,这样在WB的时候才能找到正确的rd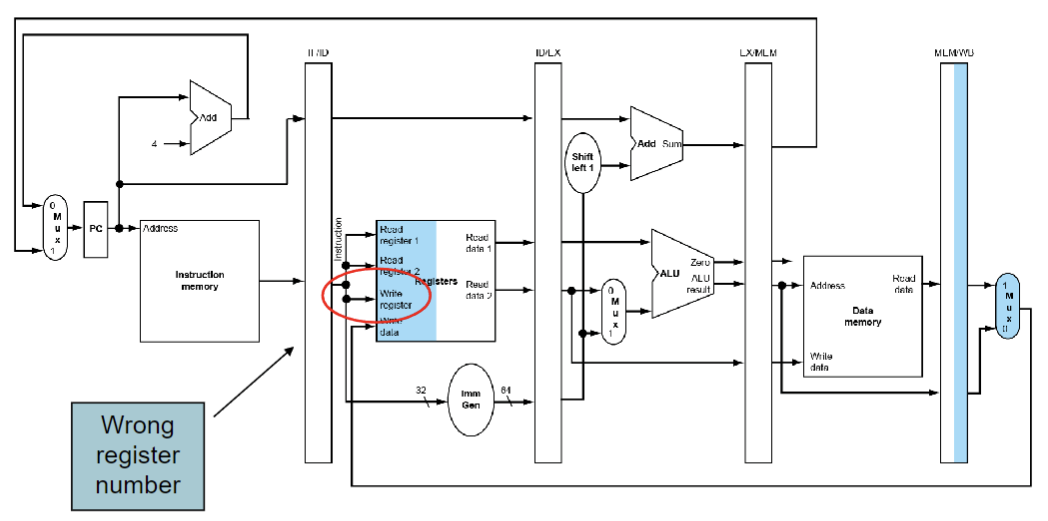
#多周期流水线示意图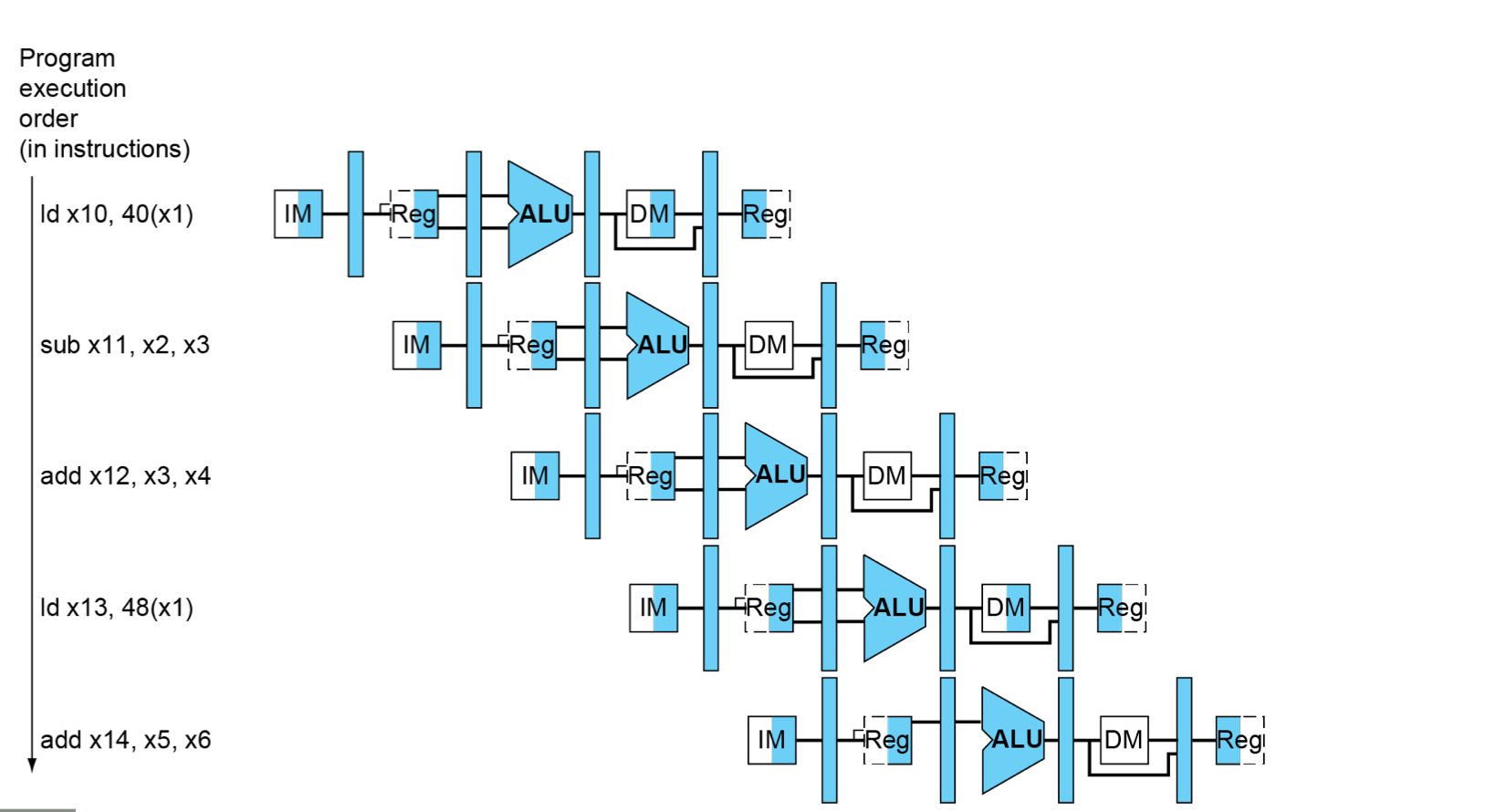
pipeline control
控制信号由指令而来
在单周期实现中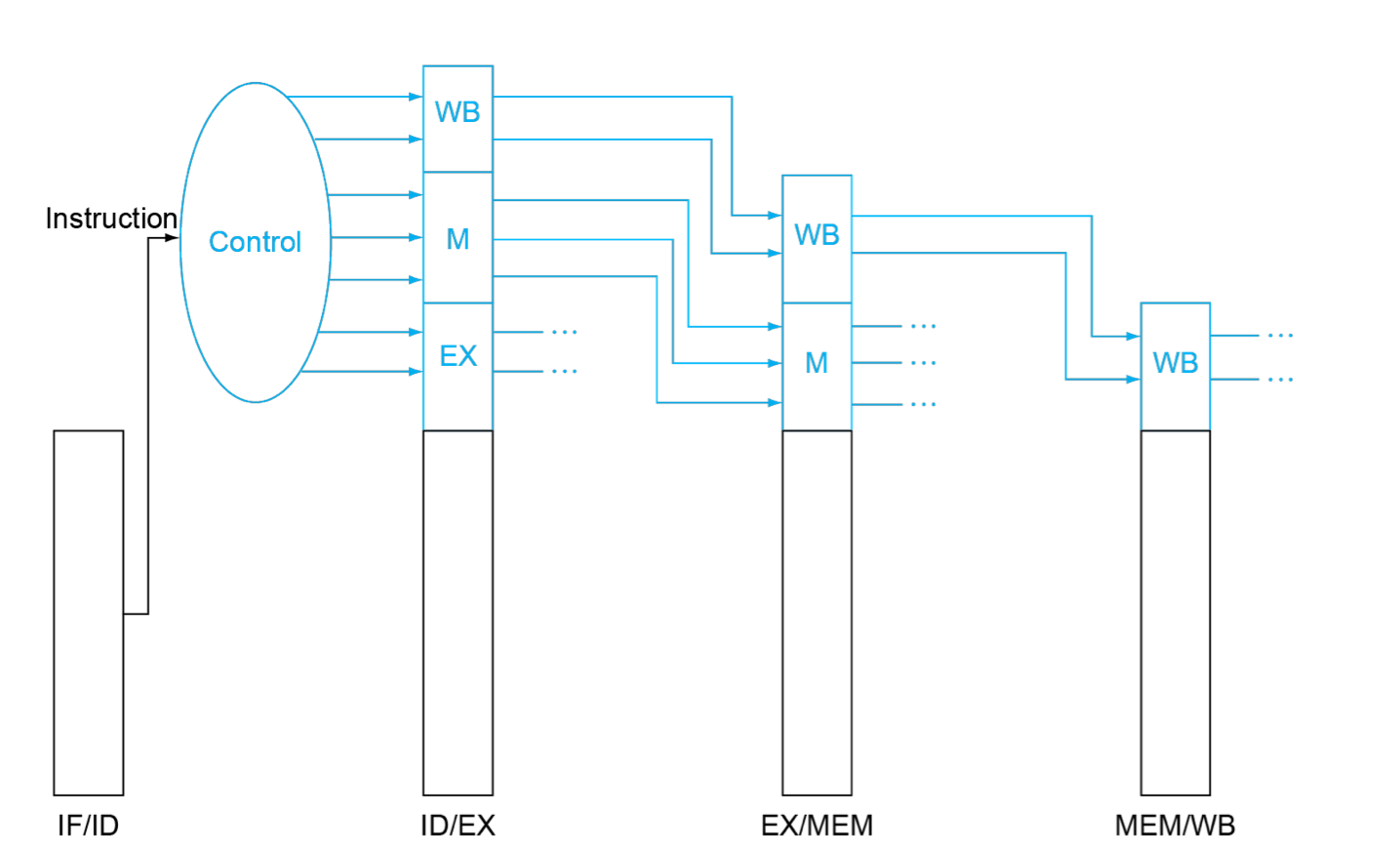
每经过一个步骤,该步骤所需要的control signal就不再需要,其余的control signal流向下一个步骤,控制后续步骤的执行
将pipeline control替换我们之前在单周期的CPU图中的control可以得到下图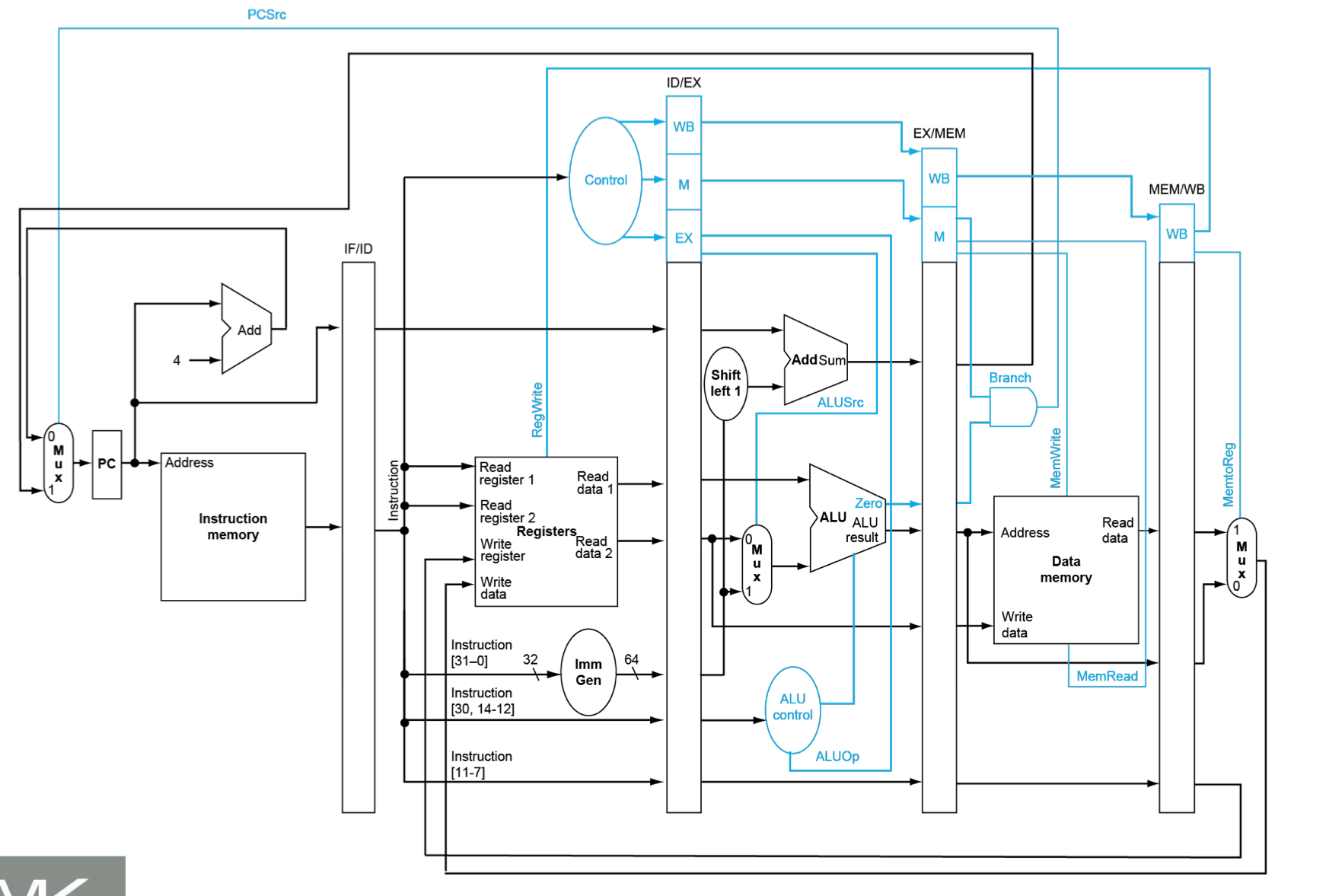
我们将上图与原来单周期的CPU图的control进行比较
- 单周期control
- 3个 multiplexer
- ALU source
- WB
- PC source
- 3个 state elemetn
- MemRead
- MemWrite
- RegWrite
- 1个 ALU op
- 3个 multiplexer
- pipeline control
- control信号跟随processing流动
- EXE 信号
- ALU op
- ALU source
- MEM 信号
- MemRead
- MemWrite
- Branch (PC source)
- WB 信号
- MemtoReg
- RegWrite
- EXE 信号
- control信号跟随processing流动
Forwarding 实例
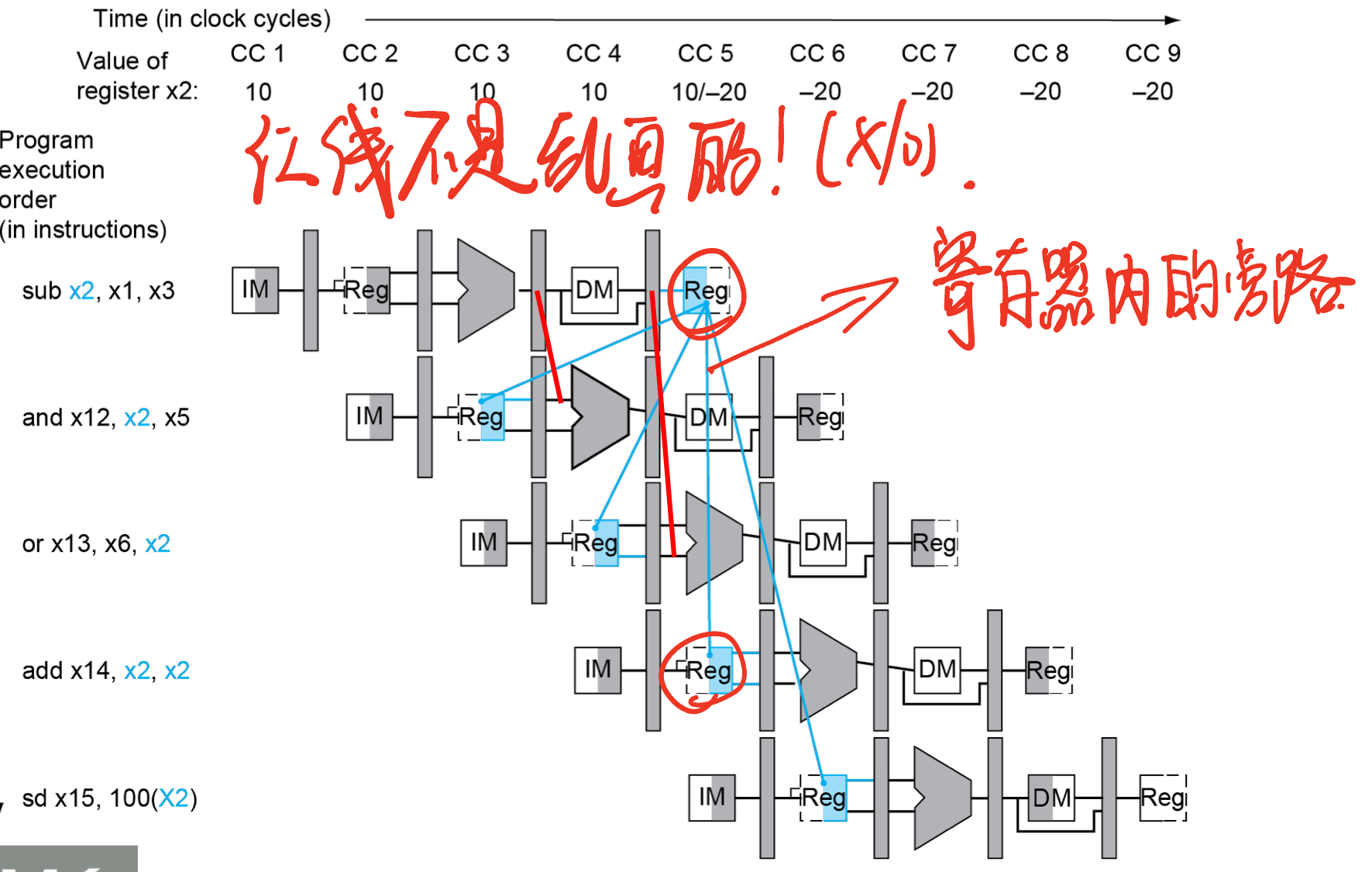
检测forwarding
核心:上一条指令rd恰是下一条指令的rs
随着流水线传递register number
- 比如:ID/EX rs1 = register number for rs1 sitting in ID/EX pipeline register
ALU 操作寄存器由 ID/EX rs1,ID/EX rs2 给出
Data hazard 发生于
- 由EX/MEM pipeline reg 发生forwarding (上一条指令rd)
- 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1
- 1b. EX/MEM.RegisterRd = ID/EX.RegisterRs2
- 由MEM/WB pipeline reg 发生forwarding(上上一条指令rd)
- 2a.MEM/WB.RegisterRd = ID/EX.RegisterRs1
- 2b.MEM/WB.RegisterRd = ID/EX.RegisterRs2
- 由EX/MEM pipeline reg 发生forwarding (上一条指令rd)
只有当要写入寄存器的时候才会发生forwarding
- EX/MEM.RegWrite,MEM/WB.RegWrite
- 检测确实有写使能的信号
只有写入寄存器不为x0时才会发生forwarding(x0不能被写)
修改forwarding的情况

也就是说,当出现双重冒险时,不再承认爷孙之间的旁路
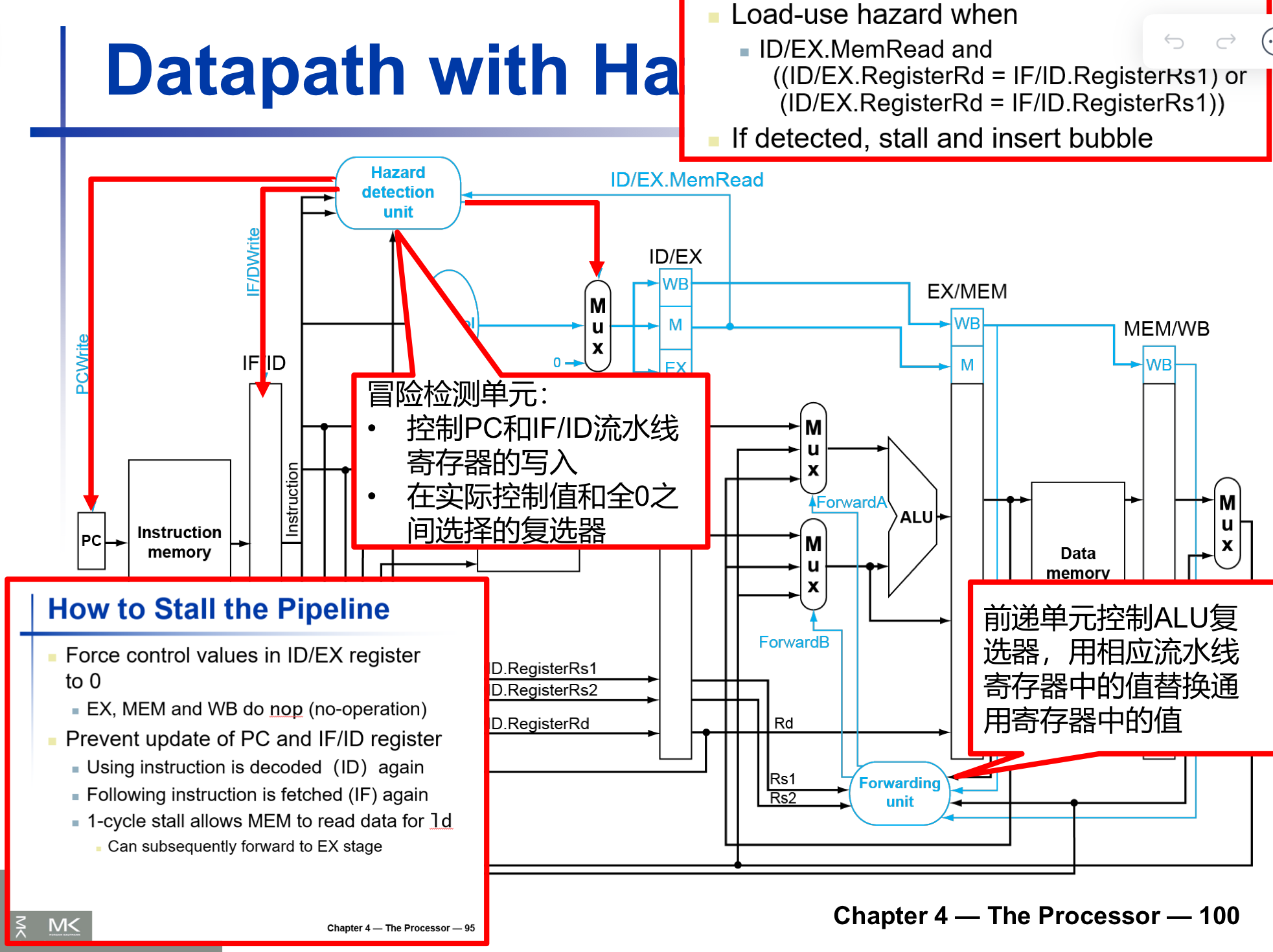
Load-Use 冒险检测
- 检测指令是否在ID阶段被编码
- ALU 操作数在ID阶段由
- IF/ID.RegisterRs1
- IF/ID.RegisterRs2 给出
- Load-Use Hazard when
- ID/EX.MemRead 有Mem读使能信号
- ID/EX.RegisterRd=IF/ID.RegisterRs1或者
- ID/EX.RegisterRd=IF/ID.RegisterRs2
- 为什么这个寄存器的检测这么奇怪?
- 我们按照正常流水线的流程来进行设想,load-use hazard发生的核心在于,下一条指令需要的rs在load-use中在Mem-WB的时候才能得出结果,但是我们检测load-use hazard 只需要 load-use rd,下一条指令rs,和mem读使能信号,这些信息我们在解码的时候就可以得出,也就是在IF/ID就可以得到了,而阻塞是如何发生的呢,当我们发出阻塞信号时,并不是流水线停止工作一个周期(流水线是不会停止的),而是我们将前面的阶段清零,如果我们检测 EX/MEM.RegisterRd=ID/EX.RegisterRs,如果我们检测到需要阻塞,就会将ID和它之前的IF都清零(因为此时我们已经加载了两个指令),那么实际上会造成两个阻塞,比我们的分析多浪费一个周期,所以我们提早一个检测也就是ID/EX.RegisterRd=IF/ID.RegisterRs
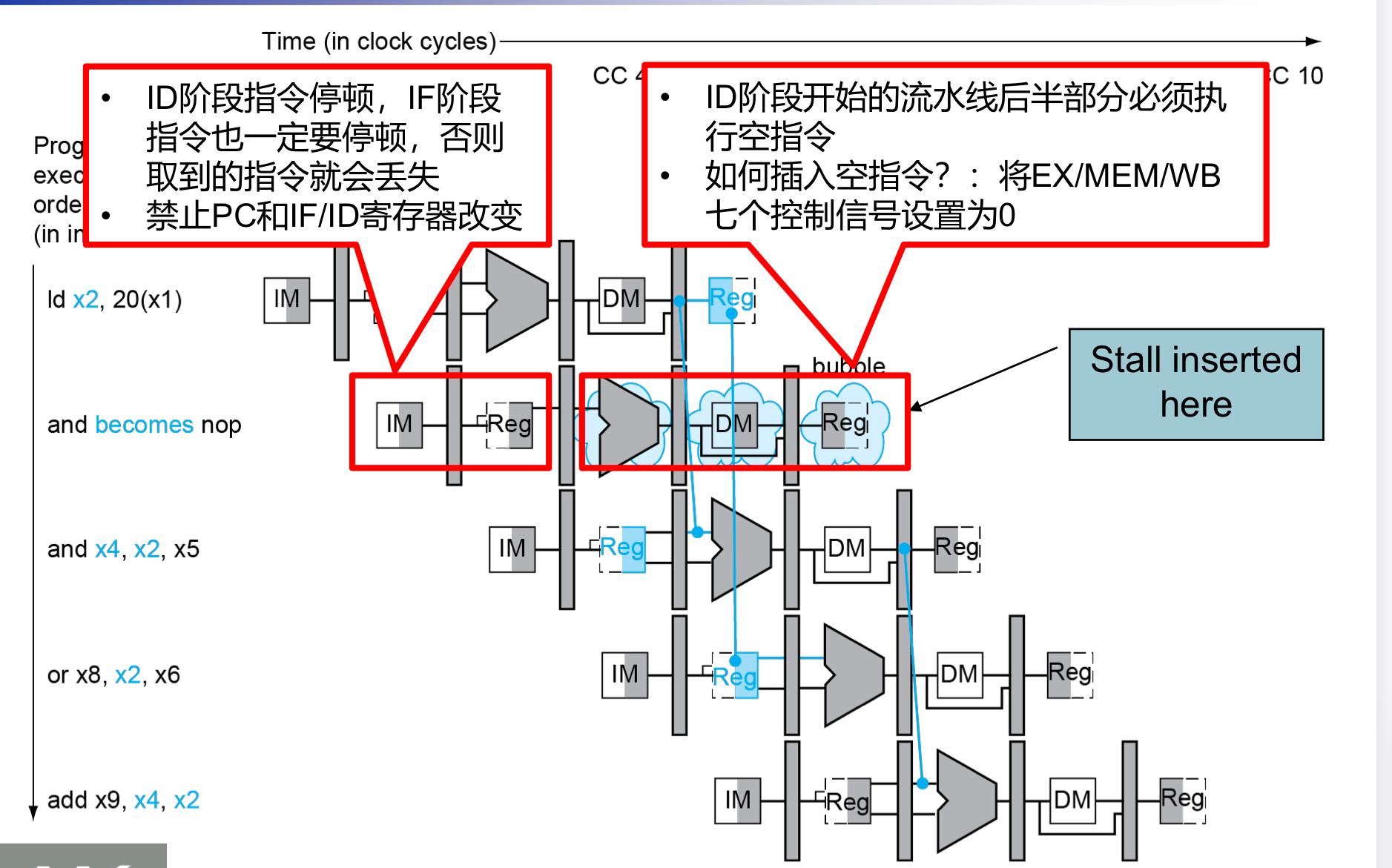
- 如果检测到确实有load-use冒险,那就阻塞并插入一个bubble
怎样在流水线中进行阻塞
- 强制ID/EX register置为0
- 控制信号全部置0,让后面的阶段都nop
- EX,MEM,WB 不做操作
- 防止PC和IF/ID register的更新
- 让PC停止更新,IF/ID流水线寄存器不发生改变,可以造成一个时钟周期的滞留
- 再一次使用已经被编码的指令
- 下一条指令会再一次被fetch
- 一个周期的阻塞可以让MEM为ld读取数据
- 可以forward到EX阶段
带有冒险检测的流水线
性能方面
- 阻塞一定会降低性能
- 但是保证了正确性
- 编译器可以通过调度代码来避免冒险和阻塞的发生(code schedule)
- 需要流水线结构的知识
Branch Hazards
如果我们在MEM才决定是否要进行分支跳转: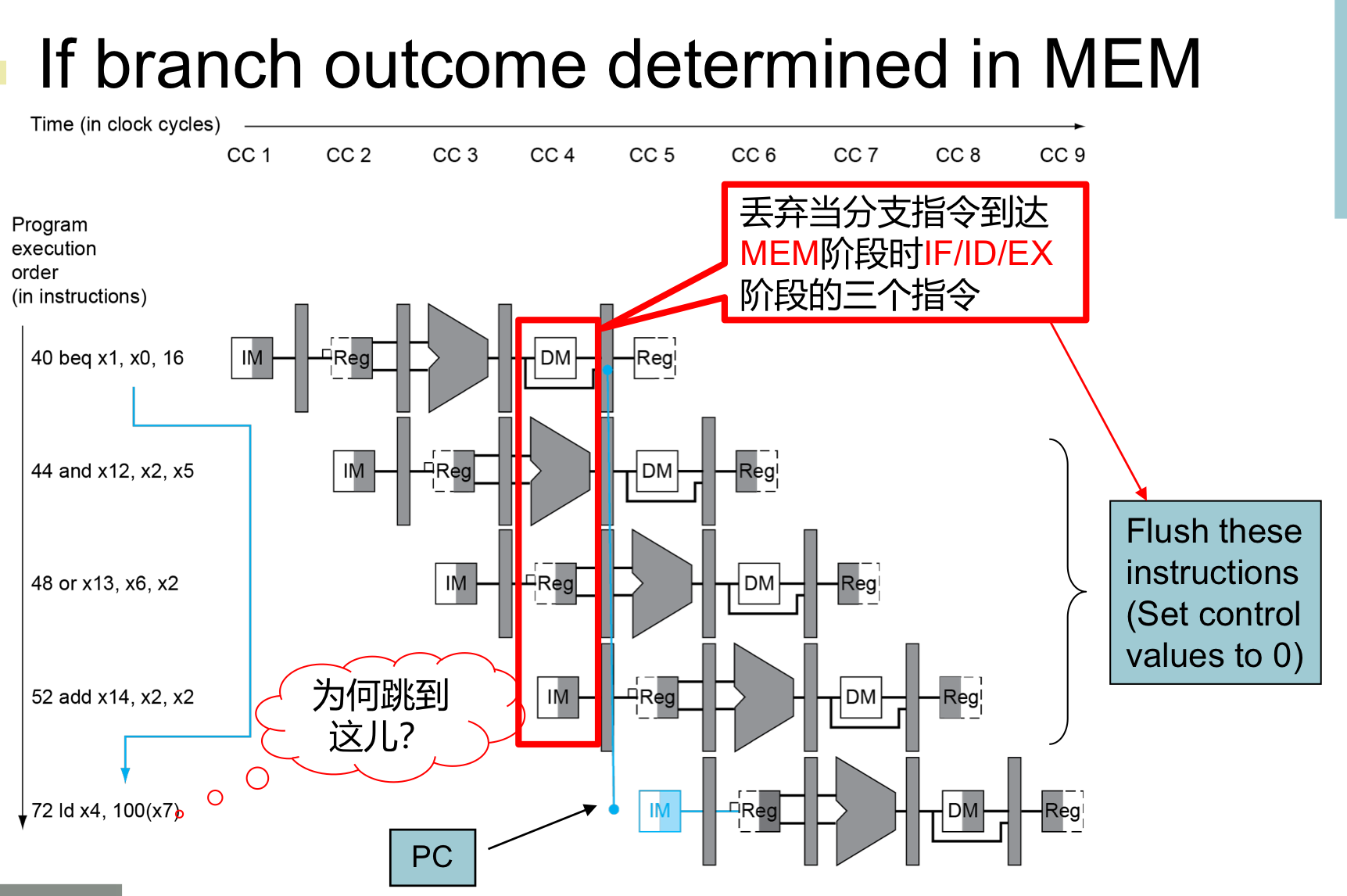
可以看到我们将前面已经加载的指令全都冲掉了,非常浪费时钟周期
削减分支跳转的延迟
- 添加硬件,使其在ID阶段就得出是否要跳转的结果
- 目标地址adder(PC相对寻址)
- register comparator (用于逻辑运算,决定是否跳转)
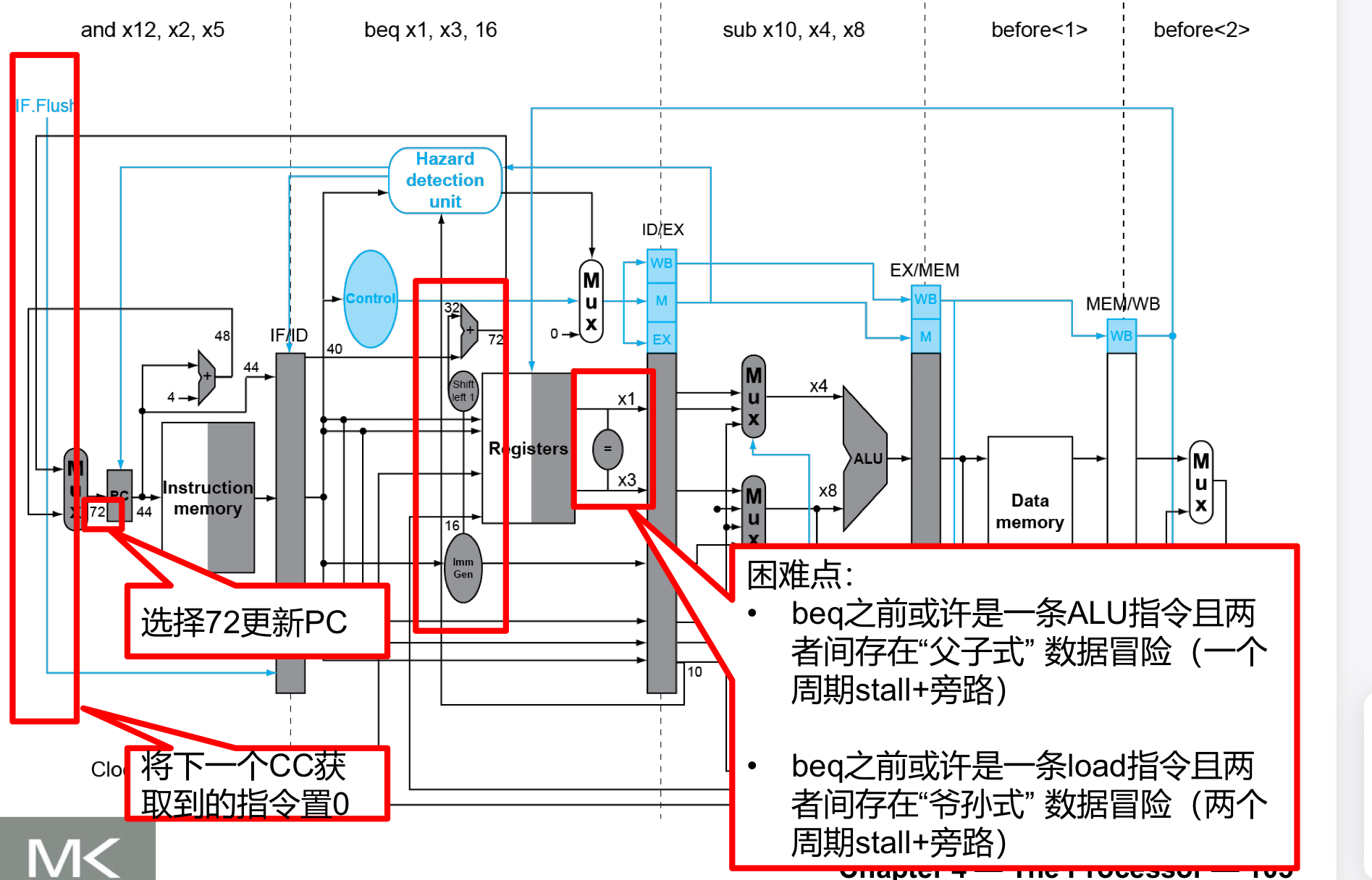
上面的流水线图我们可以看到:- 在ID阶段就已经计算出了target address,并将rs1,rs2进行了比较
- 如果判断出需要跳转,IF.Flush控制信号将IF/ID寄存器冲掉,也就是将下一个CC获取到的指令置0
注意我们要将comparator提前放置会带来很多设计上的巨大挑战
- 这里既然是一个算数逻辑运算那么就完全有可能发生data hazard
动态分支预测
- 使用动态预测
- 分支预测缓冲(也叫分支历史表)
- 由branch指令地址进行索引(lower bits)
- 存储结果(是否发生跳转)
- to 执行跳转
- 检查table,预测是相同结果
- 从fall-through或者target来取指令
- 如果预测错误,则冲跳流水线并翻转预测
1-bit 预测的缺点
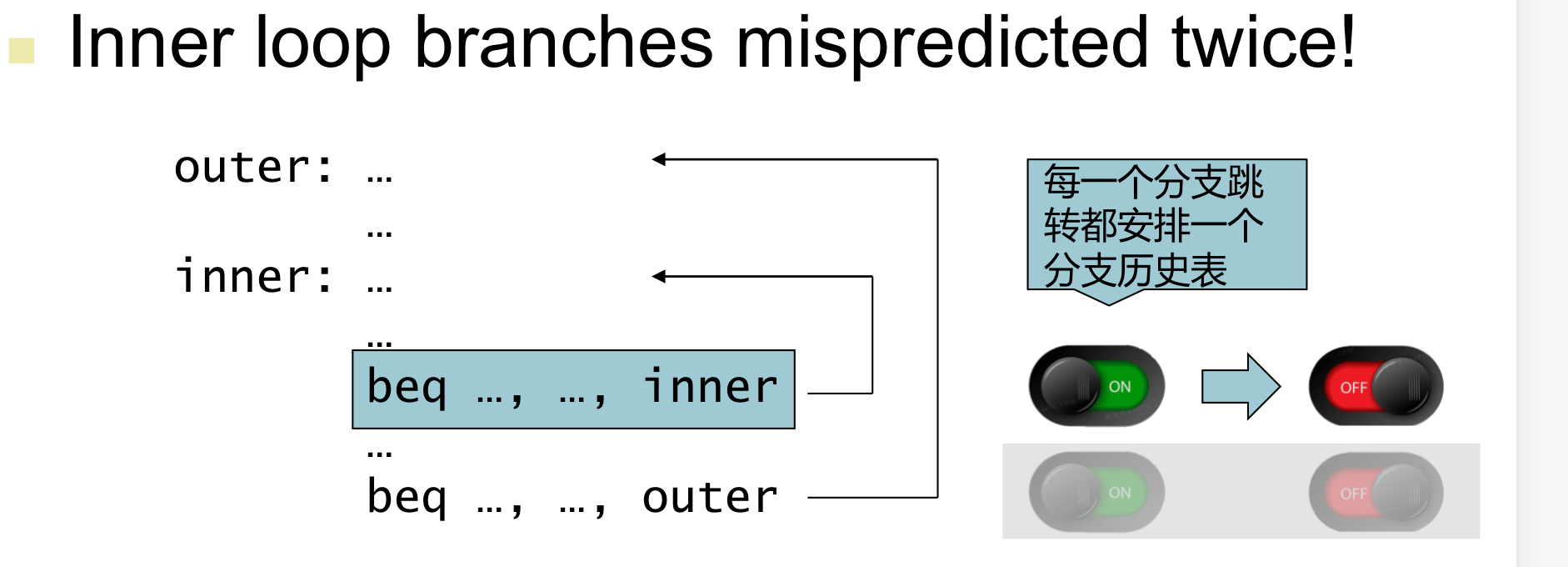
- 在inner loop的最后一次迭代的时候预测会跳结果没跳
- 在inner loop第一次迭代预测没跳结果又跳了
- 每一个分支都有它自己的分支历史表
于是我们就设计了一个 2-bit 预测
只有当连续两次发生预测错误的时候才会发生翻转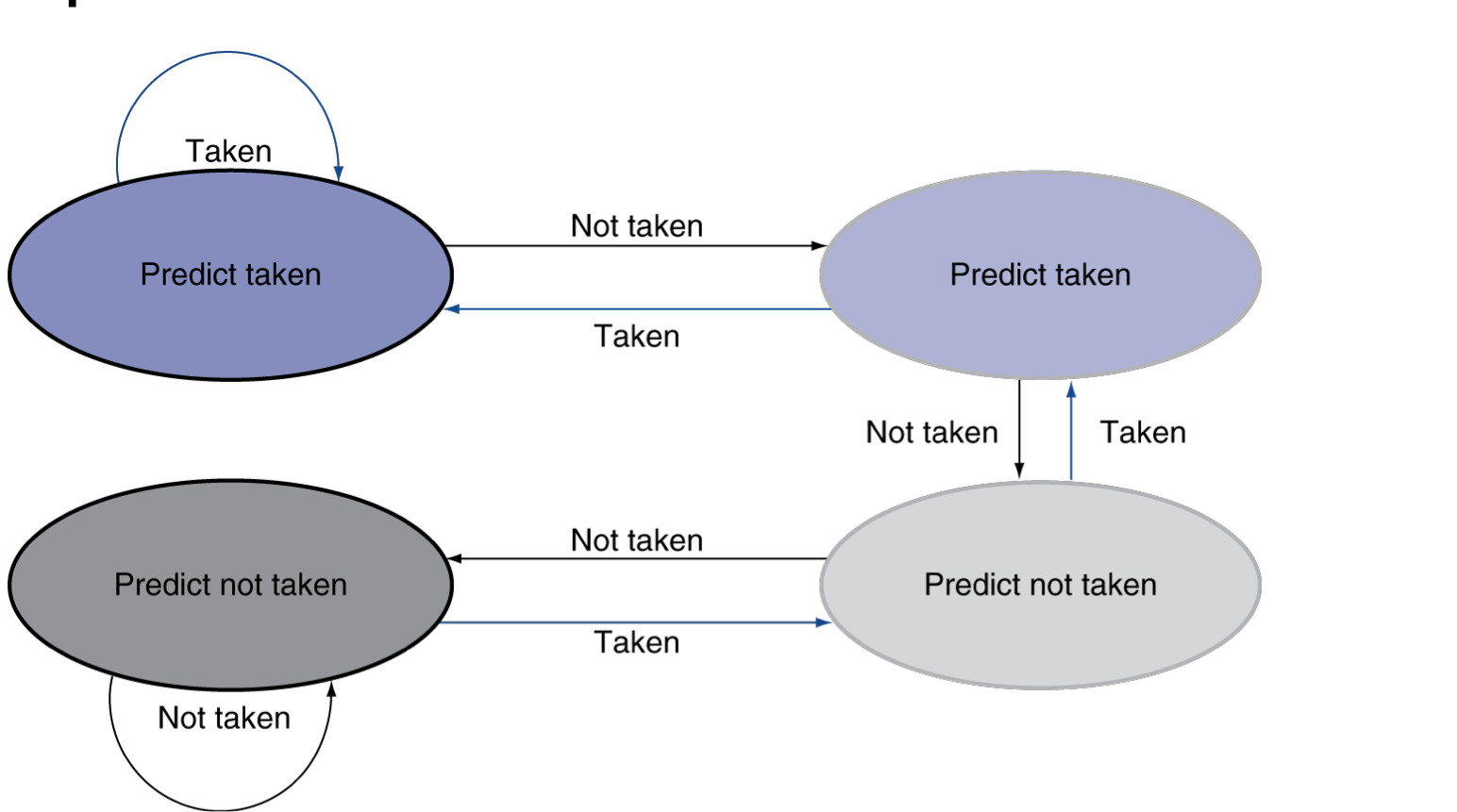
计算branch target
- 即使有预测存在,仍然需要计算target address
- 如果发生了branch那也只会发生一个周期的panalty
- 分支目标缓冲
- 存储target address(时刻准备着)
- fetch 指令的时候由PC进行索引
- 如果发生了分支跳转,可以立刻进行目标地址索引
Exception and Interrupts(例外与中断)
- 未预料到的事情在control flow过程中发生需要更改
- Exception
- 一般是由CPU引起的
- 例如没有定义的操作码,系统调用等
- Interrupt
- 从外部I/O controller引起
- 不牺牲性能是很难的
处理例外
- 将被打断的指令的PC保存下来
- 将问题的指示保存下来(原因)
- Supervisor Exception Cause Register(系统例外寄存器)
- 64bit,但是大多数都没用上
- 跳到handler
一种选择性机制
- 向量式中断
- handler的地址由原因决定
- 基址寄存器加上例外原因作为目标地址
- 指令要么处理中断要么跳到handler
handler 的行为
- 读取原因,然后跳到最相关的handler
- 决定所需的行为
- 如果可以重新开始
- 采取正确的行为
- 使用SEPC返回到program中
- 否则
- 终止程序
- 使用SEPC和SCAUSE报告错误
流水线中的例外
- 另一种形式的control hazard
- 考虑
addi x1, x2, x1在EX阶段出现例外- 防止x1被更新
- 将前面的指令正常执行完
- 将该指令和随后的指令都flush掉
- 写入SEPC和SCAUSE寄存器的值
- 将控制权移交给handler
- 与错误预测的branch很相似
- 用了很多相同的硬件
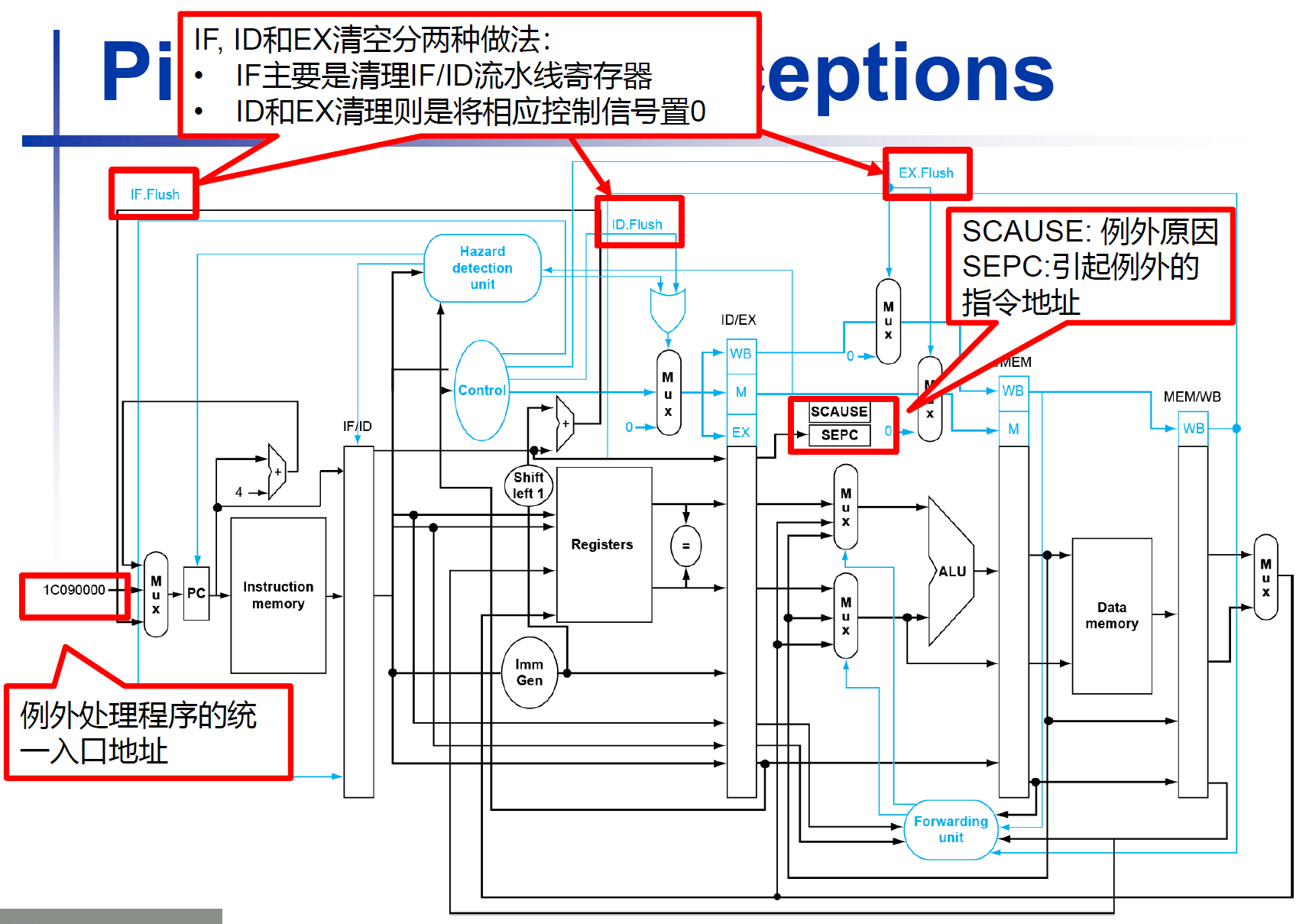
- 用了很多相同的硬件
例外的性质
- 可重开的例外
- 流水线可以冲掉指令
- handler执行之后,返回到该指令
- 重新fetch并执行
- PC在SEPC中被保存
- 查明causing instruction
例外举例

假如在上面的4c add指令发生例外,让我们看看流水线会发生什么变化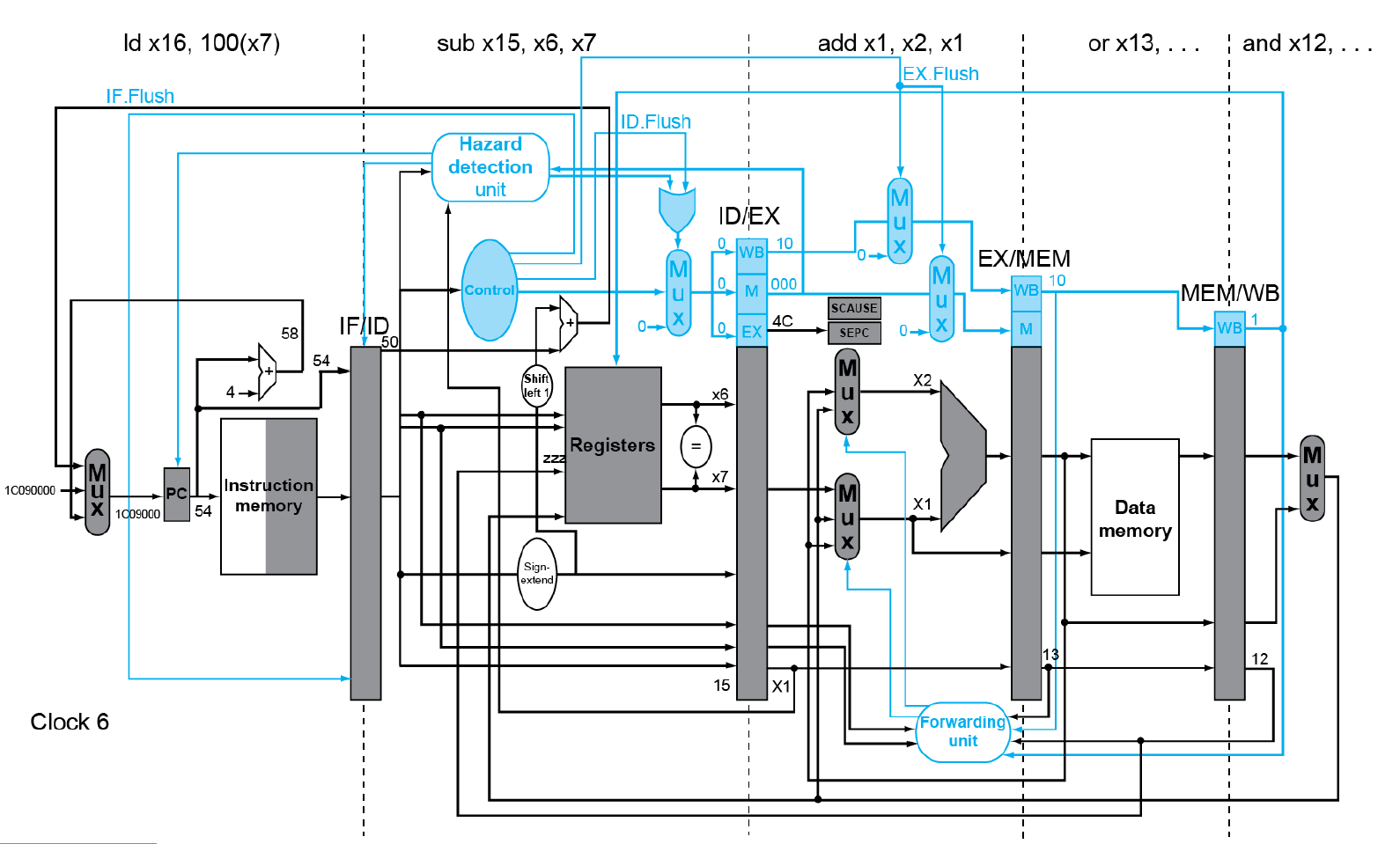
上面是发生例外时进行处理,下面可以看到处理后的流水线发生了什么变化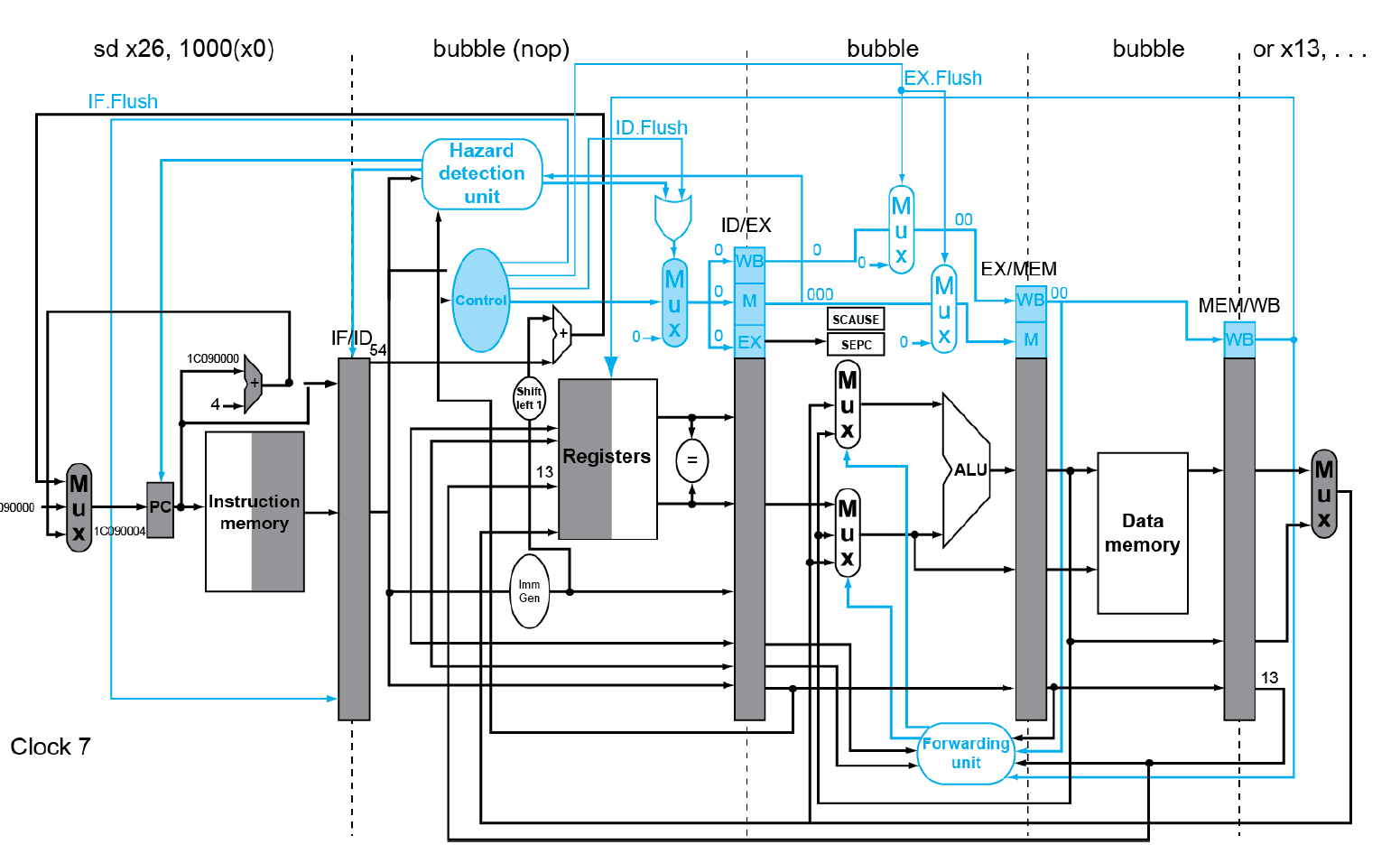
可以看到已经进行加载的指令全部flush变为bubble,并且handler中的sd指令进入流水线,也就是将控制权交给handler,执行例外处理。
多重例外
- 流水线会重载多个指令
- 可能会同时发生多个例外
- 简单的方法:从最早的指令进行处理
- 将后续的指令全部冲掉
- “精准的”例外
- 在复杂流水线中
- 每个CC中出现多个指令
- 乱序的完成
- 保持“精准的”例外是很难的
模糊例外
- 停止流水线并保存状态
- 包括例外原因
- 让handler 开始工作
- 哪些指令有例外
- 哪些需要完成或者冲掉
- 可能需要手动完成
- 简化硬件,但是复杂化软件
- 对于复杂多重问题的乱序流水线是不可行的
