
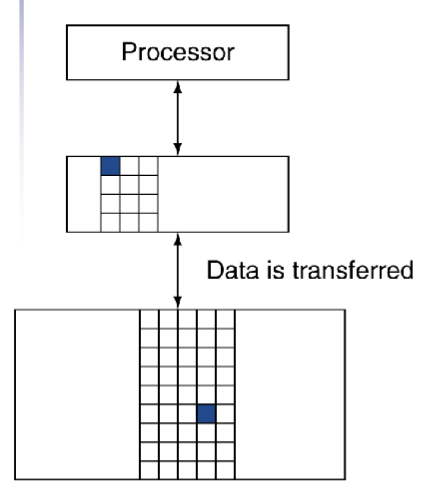
局限性原则
时间局限性
- 被访问的 item 在近期很可能会再次被访问
- 例如循环中的指令
空间局限性
- 被访问的item相邻的item后续也可能被访问
- 例如数组
利用局限性
- 使用 memory hierarchy
- 将所有东西全都存在disk中
- 将所有经常访问的或者其近邻的元素从disk复制到更小的DRAM memory中
- main memory
- 将访问更加频繁的从DRAM复制到更小的SRAM memory中
- 与 CPU 密切贴合的 Cache memory
存储层次等级
- Block(块):复制的单元
- 可能会有很多 word
- 如果被访问的数据存在于在更高的等级
- Hit:满足高等级访问
- hit ratio:hits / accesses
- Hit:满足高等级访问
- 如果要访问的数据不存在
- Miss:从低等级copy block过来
- 花费时间:miss penalty
- Miss ratio:misses / accesses = 1- hit ratio
- 然后再从高等级访问数据
- Miss:从低等级copy block过来
硬盘存储
- 非易失性,旋转的磁性存储
sector 和 访问
- 每个sector 记录
- sector ID
- 数据大小
- 纠错代码
- 用于隐藏缺陷(hide defects)并记录错误
- 同步字段
- 访问一个 sector 包含:
- 排队延迟(如果有其他访问正在进行)
- 寻找(移动机械头)
- 旋转延迟
- 传输数据
- 控制器开销
举例:
在上面的的计算中包含以下部分
- 机械头寻找的实践 seek time
- 期望的旋转延迟(所以要乘以 1/2)rotational latency
- 数据传输时间
- 控制器开销
Cache Memory
- 在存储层次中最接近CPU的部分
问题:
- 怎么放?
- 该放在那里?

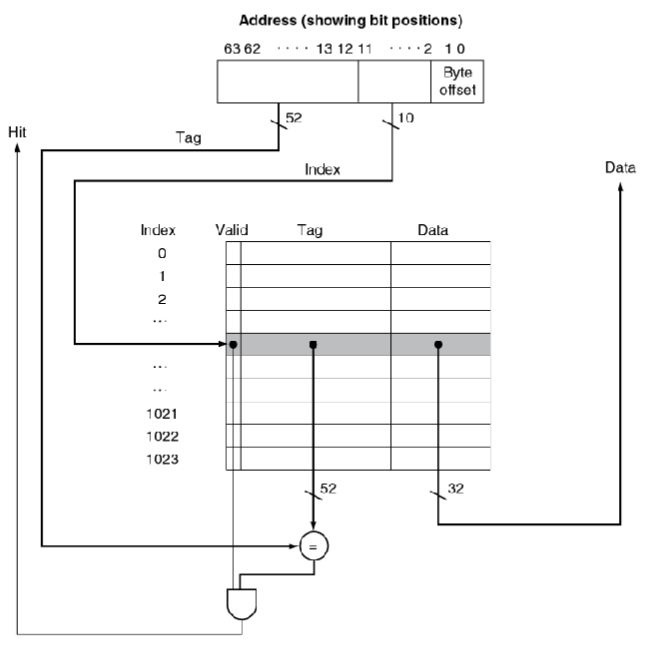
直接映射
- 存放的位置由address决定
- 直接映射:只有一个选择
- 用block的address 对 block的数量进行取模运算(也就是取地位地址)
tags 和 Valid Bits
- 我们怎么直到特定的block被存在了cache中呢(明显的是,直接映射是会发生冲突的)
- 将block address也存储起来
- 事实上只需要高位地址(我们之前取模去掉的那部分)
- 将其称为tag
- 那如果cache的这个地方没有数据呢?
- 引入Valid bit:1表示有,0表示无
- 初始为0
Cache的一般步骤
- 得到要读取的数据address
- 先看对应的cache block中是否有数据
- 有 => 核对tag
- tag 正确 => Hit
- 否则 miss
- 无 => Miss
- 有 => 核对tag
- 访问数据,或者将数据复制到对应cache块中
Address Subdivision
举例:更大的block size
- 64个block ,每个block 有 16 个byte
- 地址1200 会映射到哪个block number?
- Block address = 1200 / 16 = 75(第75个block)
- Block number = 75 % 64 = 11(在cache中放在11中)
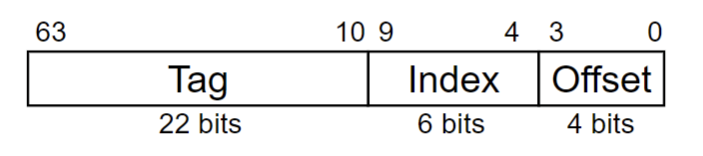
关于上面的offset:
由于我们将block作为cache 的基本单元,但实际上我们的指令操作单元或数据单元是以字节作为单位的,所以再将block进行cache之后我们还需要再cache内部进行索引,在上面的硬件电路图中,Data只有一个word,所以我们的byte offset为两位,可以对这个word中的4个字节进行索引。
而如果这个data有多个字节,比如8个,那么我们的offset 就会分为 word offset 和 byte offset两部分,word offset为3位(对8个word中的哪个进行索引),byte offset为2 位(对1个word中的哪个字节进行索引)
而一个word一定是4个字节,所以byte offset 位数是固定的(一定为2位),而word offset位数则根据data的字节数发生变化
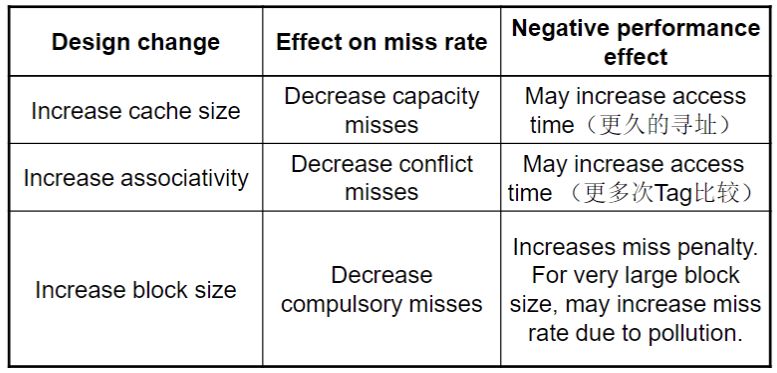
Block Size的思考
- 更大的 block size 可以降低miss rate
- 由于空间局限性,我们可以更方便的访问近邻元素
- 但是在一个一定size的cache中
- 更大的block size 会导致 更少的block 数量
- 这就会导致更多的block竞争 => 提高 miss rate
- 太大的块会导致各个字之间的空间局部性降低
- miss rate 降低带来的益处也会相应减少
- 更大的block size 会导致 更少的block 数量
- 更大的miss penalty
- 会覆盖掉降低miss rate带来的好处
- 从memory中取出block并放到cache中的时间决定了 miss penalty
- 第一个字的延迟时间
- 剩余部分block的传输时间
- 传输时间就是miss penalty,会随着block 的增大而增大,如果 miss penalty 的增大 超过了miss rate的降低,cache的性能反而会减低
- 而如果能设计得能更有效的传输较大的block时就能增加 block size 并进一步改善 cache 性能
- early restart 和 critical-word-first 可以改善
- early restart
- block 中所需要的 word 一旦返回了就可以立刻执行,不需要等到整个block 全部传输完毕
- critical-word-first
- 先传输所需要的 word,该word传输完毕后直接开始 early restart
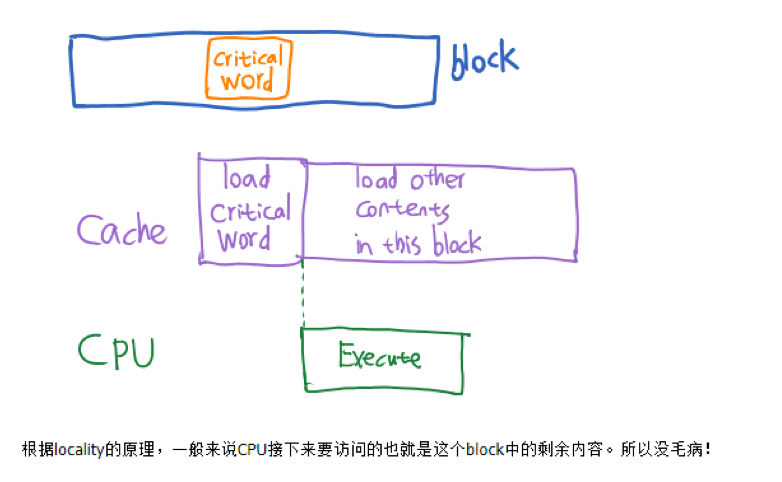
- early restart
cache miss
- 如果 hit ,那么CPU 正常进行
- 如果 miss
- 将CPU 流水线进行阻塞
- 将block 从memory fetch上来
- Instruction cache miss
- 重新开始instruction fetch
- data cache miss
- 继续完成data 访存
write-through
- data-write hit需要更新在cache 的block
- 但是这样会造成cache和memory的block不统一
- write through(写直达):同时更新memory
- 但是会造成写操作耗费更长的时间(因为访问memory的时间往往是访问cache的几个数量级)
- solution:写缓存(write buffer)
- 在cache中留一块区域将需要写回memory的数据全部存起来,稍后再一起写回
- CPU 可以正常执行
- 只有当这个buffer 满的时候才会发生阻塞
- alternative:如果data-write hit,只更新 block in cache中的值
- 设置一个dirty bit来跟踪哪个block发生了更新
- 当这个dirty block 需要被替换的时候,再写回
- 在这个dirty block 被替换的时候又可以使用 buffer 让这个新的block 被读,而不需要等待dirtyblock 写回完毕
write-Allocation
- 当write Miss的时候会发生什么呢
- 写分配法(write-allocation):fetch block 再进行写回
- 写不分配法(write around):不fetch block ,直接将其写回memory
- 多用在大量初始化的时候,在读一个数据之前会写入一整个block

- 多用在大量初始化的时候,在读一个数据之前会写入一整个block
评估 cache 性能
- CPU性能的几个组成部分
- 执行execution 周期
- 包括 cache hit 的时间
- memory 阻塞周期
- 主要是cache miss 的情况
- 执行execution 周期
- memory stall cycles
- = memory的访问比例 * miss rate * miss penalty
- cache分为 D-cache 和 I-cache,其中D-cache考虑load和store指令
- actual CPI = 理想CPI(不存在miss penalty)+ I-cache miss penalty + D-cache miss penalty
- 这里要注意一点是,所有的指令都属于I-cache,而D-cache则只考虑load 和 store指令,所以I-cache计算的时候不需要乘以一个比例数,而D-cache penalty计算的时候则要乘上load & store指令的所占比例
- Average Access Time
- 平均memory 访问时间(AMAT) = Hit time + miss rate * miss penalty
关于性能总结
- 当CPU 性能提升的时候,miss penalty 就越来越显得重要了
- 减小CPI = 提升CPU 性能 -> 更大比例的时间花费在memory 阻塞上
- 增大clock 频率 -> memory 阻塞会花费更多的CPU 周期数
- 因为提高 clock 频率 只是CPU变快了,但是memory access的时间没有变化
- 在评估系统性能的时候不能忽略cache的行为
Associative Caches
- 全相联
- 允许一个block 可以填入cache中的任意位置
- 允许所有的entry 一次性被搜索
- 每个entry都进行比较(昂贵的)
- n路组相联
- 每一个 set 都有n个entry
- block number 决定了应该填入哪个set
- (block number) modulo (#sets in cache)
- 在一个set中搜索所有的entry
- n 次比较(稍微便宜点)
关于相联性
- 提高相联性能够减小miss rate
- 但是同时会带来回报率降低(斜率降低)
置换的策略
- 直接映射 -> 不需要选择性置换
- 相联
- 首选non-valid entry
- 否则就在set中的有效的entry做选择
- LRU机制(Least-Recently used)
- 选择最长时间最少被用到的进行置换(50岁以上的出列!)
- 随机置换
- 如果我们相联中一个组内的entry很多,我们用LRU机制反而会更加繁琐,这时使用随机置换并不会造成很多的浪费
多级cache
- primary cache 与 cpu相连
- 小但非常快
- 2级cache 用于服务 primary cache misses 的情况
- 更大更慢但是仍然要比memory要快的多了
- main memory 服务 2级cache miss 的情况
多级 cache Considerations
- primary cache -> 关注于最小的hit time
- 二级cache
- 关注于低miss rate来避免访问 main memory
- hit time有更更小的全局影响
- 结果
- 一级缓存常常比单独的内存更小
- 一级缓存的block size比二级缓存的block size更小
鲁棒性(dependability)
系统会在两个状态——正常运行 & 故障修复——来回运行
- Fault:某个组件的失效
- 可能会导致系统的失效
鲁棒性的评估
- 可靠性:到达failure的平均时间(MTTF,mean time to failure)
- 服务中断:平均到达修理的时间(MTTR,mean time to repair)
- failure之间的平均时间(MTBF,Mean time between failures)
- MTBF = MTTF + MTTR
- 可用性availability = MTTF / (MTTF + MTTR)
- 提高可用性
- 增加MTTF:fault aboidance, fault tolerance, fault forecasting
- 减少MTTR:改进诊断和修理的tools and processes
虚拟内存(VM, virtual memory)
- 将main memory 作为一个“cache”来进行次要存储
- 由CPU 硬件和操作系统(OS)共同完成
- programs 会共享main memory
- 每个program会得到一个私有的保存着常用的代码和数据的地址空间
- 由其他program进行保护
- CPU 和 OS 将虚拟地址转化为物理地址
- VM “block” 被称为page
- VM translation “miss”被称为 page fault
Address translation
动机:memory 其实还是太小了,不够用
映射原理:
- CPU 会生成一个VA 来访问主存但是在访问之前需要将VA 转化为 PA
- 通过内存管理单元上的地址翻译硬件,利用存储在主存上的PT来翻译VA
Page Translation
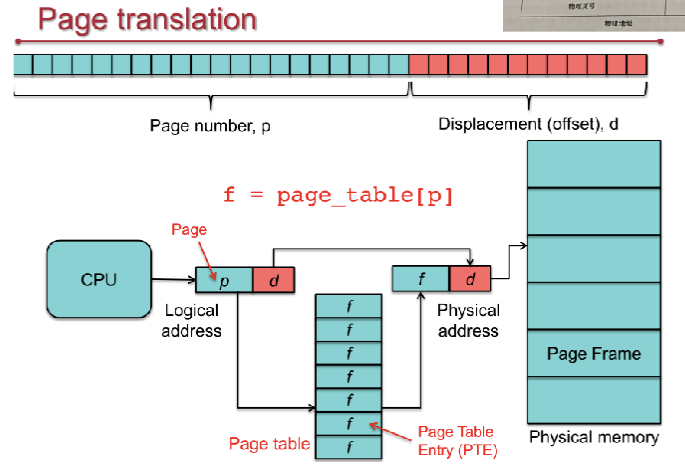
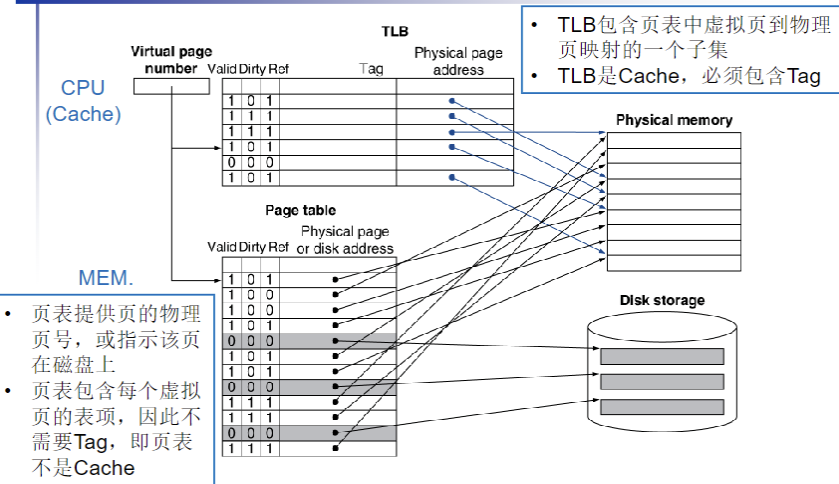
对虚拟地址进行翻译,将虚拟地址切分为VPN 和 VPO两个部分,然后通过VPN在page_table中进行查表,VPO不变,组合成一个物理地址再映射到Physical memory中
Page Fault Penalty
- 在page fault发生时,page就需要从disk中fetch
- 要花费millions级别的时钟周期!
- 由OS代码处理
- 尽力最小化page fault rate
- 进行全相联
- 用最聪明的置换策略
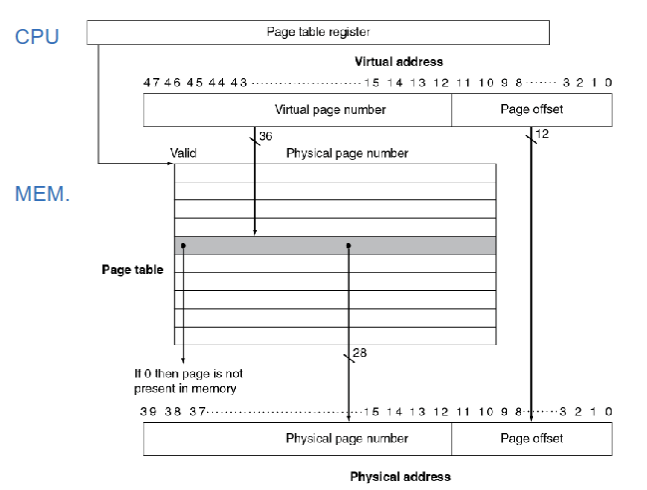
Page Tables
- 存储置换信息
- 有很多列的page table entry,由VPN进行索引
- CPU 中的 Page table register 会指向physical memory中的 page table
- 如果page是在memory中存在的
- PTE存储 PPN(physical page number)和其他的状态位(referenced(用于LRU),dirty(用于write back))
- 如果page在memory中不存在
- 那么PTE就要查询disk中的位置进行交换
- 使用page table进行translation的过程
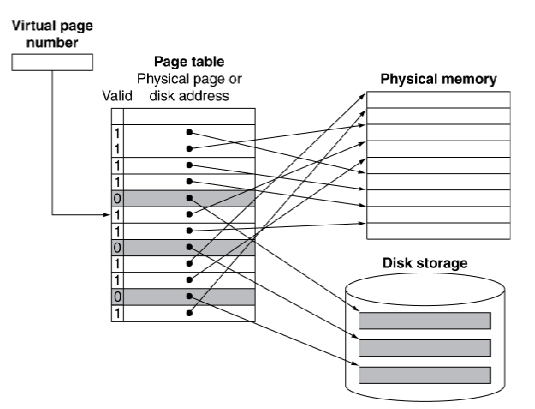
- 将pages映射到存储
置换和写策略
- 为了降低 page fault rate,会更加青睐LRU置换策略
- 当访问page的时候,reference bit会置为1
- OS会周期性的将所有reference bit全部置为0
- 一个reference bit为0的page 最近没有被使用过
- 写disk会花费million级别的周期数
- 一次要写一个block而不是单独的位置
- 写直达是不切实际的
- 使用 write-back策略
- page被写的时候PTE中的dirty bit会被置位
使用TLB 的快速translation
- address translation需要做两遍
- 一次在访问PTE
- 一次在访问真正的memory access
- 但是在访问page table的时候会有很好的局限性
- 所以在CPU中使用一小块cache来缓存PTE(这和cache的机制非常像,也就是利用locality)
- 这一个小cache被称为Translation Look-aside Buffer(TLB)
- miss会被硬软件所处理
- TLB例子
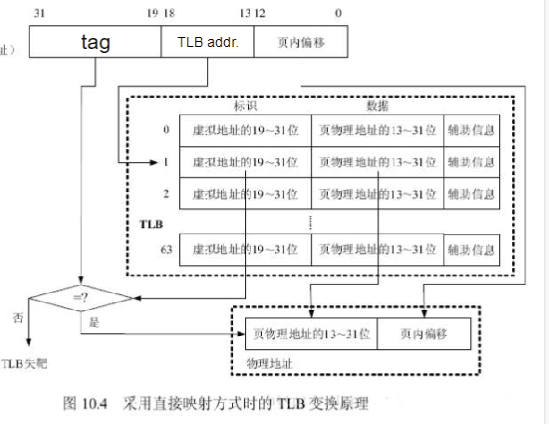
- TLB中的项被分为tag、TLB addr、offset三个部分
- 其中tag用于检查TLB是否命中,也就是核对其是否在VM中
- TLB addr则用于索引TLB条目
- 如果tag命中则提取该条目中物理地址,并与offset进行拼接
- 否则则需要查找page table 然后进行TLB的更新
TLB misses
- 如果page在memory中
- 从PTE中加载然后重试
- 可以被硬件处理
- 或者用软件
- 提出一个exception,使用优化的handler
- 如果page不在memory中(page fault)
- OS处理fetch page然后更新page table
- 然后重试faulting instruction
TLB miss handler
- TLB miss
- page 存在但是PTE不在TLB中
- page 不存在
- 目的寄存器被重写之前必须要识别TLB miss
- 提出一个exception
- handler 从memory中复制PTE到TLB中
- 然后重新执行指令
- 如果page不存在那就会触发 page fault
Page fault handler
- 使用一个 faulting virtual address来找到PTE
- 在disk中定位page
- 选择一个page 来进行置换
- 如果dirty了,那么先写回disk
- 将page读入memory然后更新page table
- 使程序重新执行
- 从faulting instruction重新开始
TLB和cache的交互
- 如果cache tag 使用物理地址
- 需要在cache lookup之前进行查询
- 使用虚拟地址
- 进行映射带来的复杂度
- 不同的virtual address 会共享相同的physical address
- 进行映射带来的复杂度
memory 保护
- 不同的进程会共享他们的一部分虚拟地址空间
- 但是需要对错误的访问进行保护
- 需要OS
- OS保护支持的硬件
- 管理模式
- 管理模式指令
- 只可由管理级别代码访问的page table和其他状态信息
- 系统调用exception
memory hierarchy
- 在每一级hierarchy
- 块可以被放在何处
- 如何找到块
- 缺失时如何替换
- 写操作如何处理
Block Placement
- 由相联性决定
- 直接映射
- n路组相联
- 全相联
- 更高的相联性会降低miss rate
- 但是会提高复杂度,成本,访问时间
找块
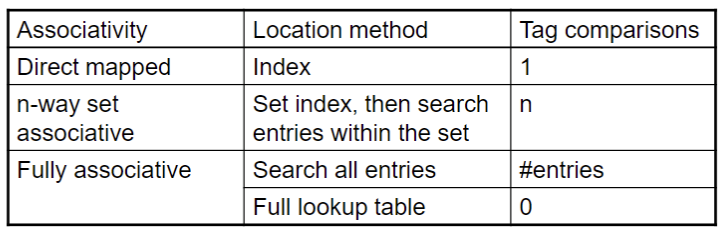
- 硬件caches
- 减少比较次数来将此花销
- 虚拟地址
- 完全的table lookup使得全相联是可行的
- 降低miss rate的好处
置换
- 在miss时的置换选择
- LRU策略
- 复杂并且对于高相联性会有大花销
- Random
- 更易实现
- LRU策略
- 虚拟内存
- 通过硬件支持近似实现LRU
写策略
- 写直达
- 简化了置换但是需要write buffer
- 写返回
- 只更新高级
- 当block被置换的时候再更新低级
- 需要保存更多的状态
- VM
- 只有写返回是可行的,disk write 太贵了
Source of misses(3C模型)
- Compulsory misses
- 对一个block的首次访问
- Capacity misses
- 有限的cache size 导致
- 一个被置换的block在随后会被再次访问到
- Conflict misses
- 在非全相联cache中出现
- 由于set中entry的竞争
- 不会在全相联中出现
cache 设计平衡

30+
Posts
8+
Diary
85+
fans